NVIDIA AI Conference 2019, 2019-7-2
올해 NVIDIA Conference 는 작년에 비해 세션 구성이 축소된 느낌을 지울 수 없다. 신기술 동향보다는 GPU 기술소개에 치중한 느낌이다. 나는 DLI Workshop 을 듣고 이튿날 Conference 를 들었다. 기조연설은 작년에 이어 올해도 Mark Hamilton 부사장이 진행하였다. Intro 및 기조연설은 좋았다. 이어서 삼성종합기술원의 심은수 센터장이 On-Device Service 측면의 기술에 대해서 소개하였다. 오후 세션중에 인상적이었던 부분은 Multi-GPU 를 활용한 딥러닝 학습에 대한 부분이었는데, 자리에 모인 개발자들도 잘 모르는 최신 기술부분에 대한 소개가 이어졌다. 정확히 적용하기가 쉽지는 않겠다는 생각이 들었다. 모든 걸 다 알고 적용하는 엔지니어가 얼마나 될까란 생각이 들었다. 제대로 세팅을 하지 않으면 Multi-GPU 자원을 제대로 활용하기 어렵다. 최종 경품행사까지 남아 있지 않고 적당한 시기에 행사장을 빠져 나왔다. 내년에는 내용이 좀 더 알차게 구성되어 끝까지 자리를 뜨지 않도록 되었으면 좋겠다.
1. Keynote Speech, Mark Hamilton VP
NVIDIA 의 성장
NGC : NVIDIA GPU CLOUD Application Acceleration Stacks

ARM 인수
AI Mechanism ( → PLAN → PERCEIVE ( from Sensors ) → REASON → ( to Actuators ) → )

SATURNV : The World Largest Enterprise AI Infrastructure Buildout
Announcing Jetson Nano

Announcing ISAAC Open SDK
Drive Initiative
Clara AI Toolkit ( Medical )
GeForce NOW : Play PC Games on any device with the power of GeForce GPUs in the cloud
2. Customer Keynote, 심은수 센터장, 삼성종합기술원
On-Device Learning 을 위한 기술 개발 中
└ Memory Bandwidth Bottleneck -> Algorithm innovation, Near-Memory/In-Memory Computing
└ Continuous Learning is essential
└ Cannot carry all the training data

3. Track5, Multi GPU Training, 유현곤 부장, NVIDIA ( 개인적으로 정리해 놓은 내용 요약입니다 )
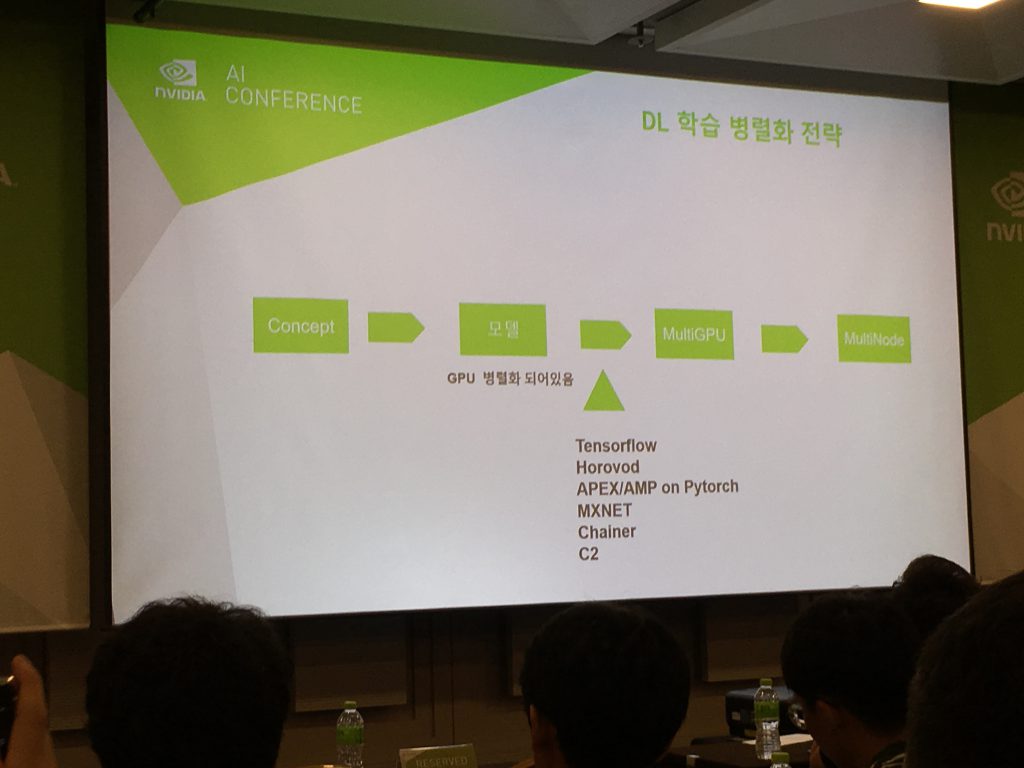
→ DGX SuperPOD : 96 DGX-2H, 1536 Tesla V100
→ NGC : NVIDIA GPU CLOUD (DockerHub 의 NVIDIA Version)
→ DGX-2 POD // DGX-1 POD ( One-Stop )
→ GPU 간 통신 : P2P 방식
→ NV Switch : DL 파라미터 전송에 사용됨
→ 병렬처리로 PI 계산하기 : 기존 CPU Program 에서 Reduction 적용 필요 (OpenMP vs. OpenACC)
→ Multi GPU 사용시 문제 상황들 : 16일 이후에 터짐 // 첫 GPU 만 메모리를 많이 씀 // GPU idel 로 변경 됨 // 문제는 없는데 수행 속도가 빠르지 않음 // 전처리시 GPU 연산 때문에 버벅거림
→ Data Loader 설계를 잘해야 한다.
└ Google GNMT / Transformer, BERT, GPT-02, XLNet / Open AI’s GLOW
└ NVIDIA’s PGGAN, Style GAN, WaveGlow
→ NGC 를 써라. NGC Model Script
→ 구체적인 접근 1. Template
└ jasper-pytorch
└ Tacotron2 pytorch
└ WaveGlow pytorch (APEX)
→ 구체적인 접근 2.
└ Batch -> Batch / GPU
└ Torch.nn.DataParallel : 0번 GPU 메모리 사용량 증가
=> Torch.nn.parallelDistributedDataParallel (Train script), args.batch_size / ngpu_per_node