
AI Festival, 2019-7-6 (토), 대전
소프트뱅크벤처스가 투자한 국내외 주요 회사들의 발표 세션 및 AI 현재 현황, 음악작곡이나 사진편집, Style 변환 등의 주제 영역과 Young Scientist 발표 등을 참관했다. 현관에는 악보를 자동으로 Midi 로 변환해서 연주해 주는 피아노가 음악을 연주하고, AI Atelier 에서는 Style Transfer 로 생성한 그림들을 전시하고 있었다. 대중적으로 접근하기 위한 좋은 행사였던거 같다. Tomocube 의 2,4,8 원칙이 인상 깊었다. 그리고 영 사이언티스트들이 논문을 읽고, NIPS 에 게재 했다는 걸 들었을 땐 충격을 받기도 했다. 간략한 노트를 작성해 보았다.






1. 소프트뱅크벤처스, 이준표 대표이사
- 1900년 New York 5th Ave. 마차들 사이의 1대의 자동차
- 1913년 대부분 자동차로 변경 됨.
<AI 는 인류 최대의 혁명>
인터넷 → IoT → AI (Deep Learning)
Life Log
2. ObeN, Nikhil Jain, CEO
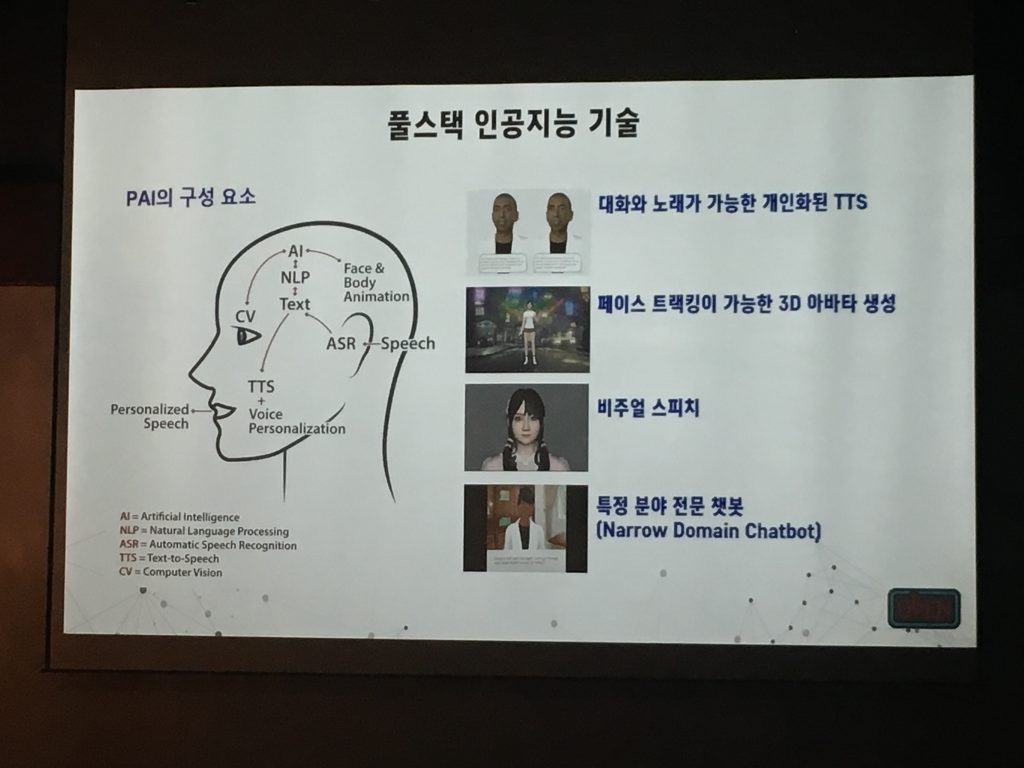
Caltec 출신 엔지니어들이 만든 아바타 회사
3. Lunit (루닛), 서범석 대표
암 진단 및 치료영역
2013년 설립
루닛 인사이트
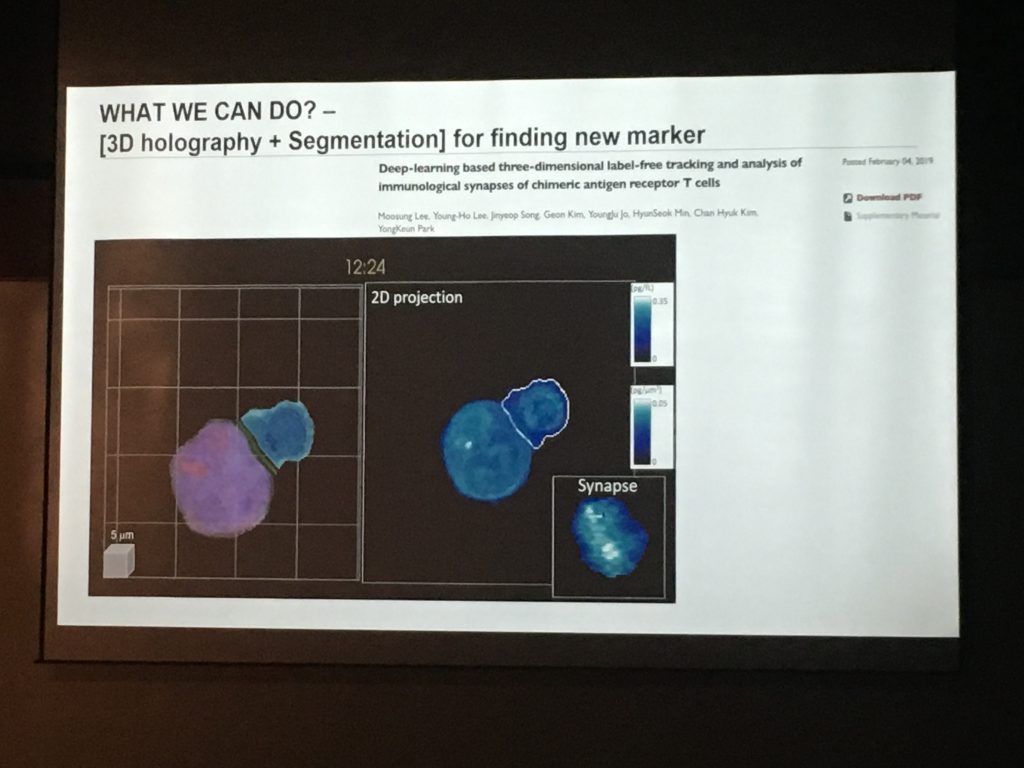
4. TomoCube, 민현석 Engineer
현미경 만들던 회사
Holotomography (HT)
‘AI 를 지운다’ -> 오해를 지운다. 6개월 동안 3명의 엔지니어와 2명의 인턴이 딥러닝 적용
Dirty Job First -> 누구보다 데이터를 많이 만진다. ( 똥 만진다 )
2, 4, 8 원칙 -> 원칙이 안 지켜지는 것은 다른 데서 잘 만들 것으로 생각
AI 기술을 만드는 쪽보다 잘 사용하는데 초점을 맞췄다.

5. Speclipse, 민완기 CTO
AI-Based Skin Cancer Diagnostics
Spectra-Scope
6. 인공지능 어디까지 왔나?, 정지훈 경희 사이버대 교수
machine intelligence landscape
Image & Video -> 상용화 단계
GAN, VAE, Flow-based generative model
NVIDIA playground : GauGAN
NEOSAPIENCE : Sound Generation
7. 인공지능 시대의 사진편집, 조영주, ETRI
SC-FEGAN
인공지능, 이미지 (맞추기 → 생성 (화가) )
시작, 2014년, Ian Goodfellow, GAN, 16*16 image, from Noise
가능성 시작, 2016년, Google DCGAN (ICLR 2016), 64*64 image, color image 생성 및 조작
활용법의 다양화, 2016년~, Pix2Pix : Image-to-Image Translation with Conditional Adversarial Networks
고도화, 2017년~, A Style-Based Generator Architecture for generative Adversarial Networks
DeepFake, Deep Video Portraits, Siggraph 2018
Image Inpainting for Irregular Holes using Portrait Convolutions
8. AI 가 만드는 음악, 이일구, 모두의 연구소
Google Magenta, Make Music and Art Using ML
음정 생성 (RNN) -> 실제로는 코드, 화음, 리듬, 세기, 비트 모두 고려 필요
데이터의 종류 : MIDI // Piano Roll // Text // Lead Sheet // Wave
1) WaveNet :
– 오디오 자체를 바로 생성
– autoregressive
– very high temporal resolution
– Naive causal convolution
– 만드는데 오래 걸림, 1초 생성하는데 2분
– Latent code 를 컨트롤 할 수 없다.
2) Performance RNN
– 음악의 표현방법 자체를 예측
3) Music VAE
– Latent Space Interpolation
– A hierarchical latent vector model for learning long-term structure in music
4) Music Transformer
5) MuseNet (OpenAI)
– 10가지 악기로 4분 짜리 음악
– GPT-2 기술사용; Large-scale Transformer
9. Dive into AI Robotics, 양서연, LG전자 로봇사업센터
ANI (약 인공지능) : Artificial Narrow Intelligence
AGI (강 인공지능) : Artificial General Intelligence
ASI (수퍼 인공지능) : Artificial Super Intelligence
Image
classification : 이미지 분류
localization : 사진에서 물체의 중심점 위치는 아는 것
detection : 물체의 종류와 위치를 아는 것
segmentation : 물체의 픽셀 위치를 아는 것
└ semantic segmentation : 같은 종류는 같은 색
└ instance segmentation : 같은 종류에서도 객체를 구분
10. AI Atelier, 이수진, 인공지능 연구원
사진 : 인간 뇌 세포에 저장한 이미지를 공유하고자 하는 욕망
Gene Kogan : Machine Learning Artist
Prisma App
기술을 응용한 창작의 세계 연구동향
– AI Experiments with Google
누구나 예술을 향유
시대를 반영하는 표현도구
인간의 감각기관 확장
예술이 예술일 수 있도록 기술을 도와줘야
11. Advancing AI for everyone, 김윤기, 동탄고
– 시작장애인 보행로 안내 App
– 수화 번역 AI
– 모르더라도 일단 해 보자
12. 흔한 고등학생의 AI 도전기, 강태원
13. 딥러닝의 넓은 세계, 지영채, 한양대 1학년
14. AI for Newbies, 이채영, 예일대
– Conditional Wave-GAN
1) 리소스 확보
2) 객관적인 성과 만들기 : Paper // Blog // GitHub
3) 뉴럴넷 구현하기 :
경량모델로 시작
열번 실험보다는 한 번 생각하기
네트워크 학습을 전략적으로 ( A Recipe for Training Neural Networks )
OpenSource 와 논문 비교하기
15. 머신러닝을 통해 보는 게임의 미래, 정선우
게임 디자이너 관점
– 더 아름다운 비주얼
– 방대한 세계
– 새로운 경험
1) Game Playing Bots :
– Play Testing
– In-Game
2) Content Generation :
– Asset Creation : Model / Character / Texture
– Procedural Generation (PCG) : 창작물과 데이터를 만들어내는 활동
-> Face // 3D Model // Texture // Voice
3) SuperSampling : Final Fantasy7 이나 고전 게임들