이전 포스트에서는 객체지향 프로그래밍의 개념에 대해 소개하였다. 동일한 주제로 Case Study 에 대한 내용을 추가로 소개하고자 한다. 이번 Case Study 를 보고나면 객체지향 프로그래밍을 진행하는 기본 개념을 익힐 수 있을 것이라 생각한다.
이 시스템은 도서관 카탈로그를 모델링 한다. 도서관들은 오랫동안 그들의 서가 정보를 검색하는 방법을 만들어 왔다. 예를 들자면, 카드 색인등을 사용했었고, 최근에는 전자 서지 정보를 활용하고 있다. 현대의 도서관들은 웹 기반의 카탈로그를 만들어 색인 검색을 제공하고 있다. 먼저 시스템을 개발하기 위해 분석(analysis) 부터 진행해 보자. 지역 도서관 사서는 구닥다리 DOS 기반의 프로그램 대신, 새로운 카드 카탈로그 프로그램을 만들어 줄 것을 요구하고 있다. 이것만으로는 디테일을 알 수는 없지만 더 많은 정보를 요구하기 전에 먼저 도서관 카탈로그가 무언인지 좀 살펴보자.
카탈로그는 도서의 목록을 보관한다. 사람들은 특정 주제나 어떤 제목 혹은 저자로 검색을 한다. 책들은 ISBN (International Standard Book Number) 인덱스로 유일하게 분류된다. 각 책들은 DDS (Dewey Decimal System) 번호를 부여받아 특정 서가에 할당된다.
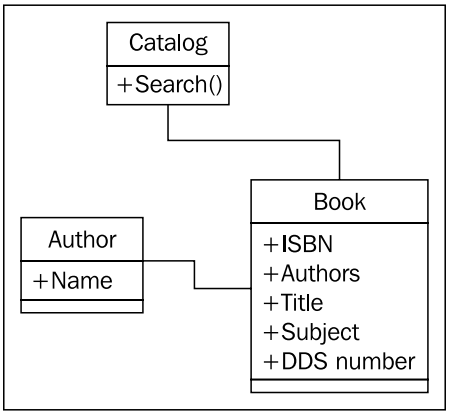
단순한 분석만으로도 어떤 객체들이 우리 시스템에 필요한지 알 수 있다. 책 (book) 이란 객체는 저자 (author), 제목 (title), 주제 (subject), ISBN, DDS 번호를 갖고, 해당 책이 속한 카탈로그 (catalog) 라는 객체를 갖는 다는 사실을 알아 낼 수 있다.
그리고 일부 포함되거나 포함되지 말아야 할 다른 객체들도 알 수 있다. 카탈로그의 목적으로, 저자 기준의 검색에서는 저자 명 ( author_name ) 이 있어야 하고, 저자 ( author ) 자체도 하나의 객체이며, 어떤 데이터 값들을 갖는 다는 것을 알 수 있다. 호기심을 좀 더 발휘해 보면 책은 여러 명의 저자를 가질 수도 있으므로, 저자 명 ( author_name ) 이라는 속성은 알맞지 않을 수도 있겠다는 생각이 든다. 따라서 저자 명 보다는 저자 목록 ( list of authors ) 가 더 명확하다. 저자 (author) 객체와 책 (book) 객체의 관계는 연관 (association) 이 된다. 헷갈린다면, “책은 저자다” ( book is an author ) 가 말이 되지 않기 때문에 상속 (inheritance) 가 아니고, “책은 저자를 갖고 있다.” ( book has an author ) 역시 저자가 책의 일부가 아니므로 ( aggregation 이 아니다 ) 말이 되지 않는다. 한편, 어떤 저자는 여러 책에 연관 (associated) 되어 있기도 하다.
또한 명사 (noun) shelf 에 주목 할 필요가 있다. (명사들은 항상 객체를 정의하는 주요한 후보들 중 하나이다. ) 서가 (shelf) 가 카탈로그 시스템으로 모델링 될 필요가 있을까? 만약 어떤 책이 서가 젤 마지막에 꽂혔다가 새로운 책이 사이에 꽂혀서 다음 서가로 밀려난 다고 하면 어떻게 될 것인가?
서가 번호인 DDS 는 책을 물리적으로 위치시킬 때 사용된다. 따라서 서가 (shelf) 를 모델링 하는 대신, 책 (book) 에 DDS 번호를 저장하는 것만으로도 충분하다. 따라서 지금 단계에서 서가 (shelf) 라는 객체는 모델에서 삭제시켜도 될 것 같다.
또 다른 문제의 객체는 사용자 (user) 이다. 우리가 카탈로그 시스템을 설계하면서 특정 사용자의 정보에 대해서 알아야 되는게 있을까? 이름, 주소, 연체 기간 같은 것들 ? 지금까지 사서는 카탈로그에 관한 요구사항을 말했을 뿐이다. 구독이나 연체 정보의 추적 따위에 대해서는 어떤 요구사항도 얘기하지 않았다. 다시 차분히 생각해 보면, 우리는 저자 (author) 와 사용자 (user) 가 어떤 형태의 사람 (people) 이라는 것을 알 수 있다. 아마도 나중에는 상속 (inheritance) 의 개념을 적용 시킬 수 있지 않을까?
카탈로그의 목적상, 우리는 사용자 (user) 를 객체로 만들지 않아도 된다. 사용자들이 카탈로그 시스템에서 검색을 할 것이지만, 그것을 시스템에 당장 모델링 할 필요는 없다.
지금까지 책 (book) 에 대한 몇 가지 속성 (attribute) 들을 확인했다. 하지만 카탈로그 (catalog) 는 어떤 속성들을 갖고 있어야 할까? 도서관 (library) 이 하나 이상의 카탈로그 (catalog) 를 갖을 수 있을까? 우리는 그것들을 유일하게 식별할 수 있어야 할까? 분명한 것은 카탈로그는 여러 책들의 목록을 보유하고 있다는 점이다. 하지만 이 목록이 공개 인터페이스 (public interface) 의 일부는 아닐 것이다.
행위 (behavior) 에 대한 부분은 어떤가? 카탈로그가 검색 (search) 메쏘드를 갖는 다는 것은 자명하다. 그 검색은 저자 (author), 제목 (title), 그리고 주제 (subject) 로 나눠질 것이다. 그렇다면 책 (book) 에는 어떤 행위가 존재하지 않을까? 미리보기 (preview) 메쏘드 갖은 것들은 필요 없는 것일까? 아니면 메쏘드 대신 그냥 처음 몇 페이지들을 보여주는 형태의 속성 정보가 되어야 하는 것일까?
앞선 이런 종류의 질문들이 모두 객체지향 분석 ( object-oriented analysis ) 단계에 속한다. 하지만 이런 질문들을 합쳐서, 이미 몇 가지 주요 객체들을 확인하였다. 사실은 여러분이 지금까지 살펴보았던 것들이 분석과 설계 단계 사이를 오가는 자잘한 반복들이었다. 마찬가지로 이런 반복들은 사서와의 미팅에서도 지속적으로 일어난다. 이 미팅 전에 지금까지 파악한 내용으로 대략적인 컨셉 설계를 해 본다면 아래와 같을 것이다.
기본적인 설계와 그것을 수정할 연필을 갖고서 도서관 사서를 만났다. 그들은 기본 컨셉에는 동의했지만, 이 도서관은 책 ( book ) 들만 있는 것이 아니라, DVD 타이틀이나 잡지, CD 타이틀도 갖고 있다고 했다. 그리고 이것들은 ISBN 이나 서가 번호인 DDS 번호가 부여되지 않는다고 했다. 이런 종류의 기록물들은 모두 UPC 번호가 대신 사용되고 있었다. 우리는 도서관 사서들에게 이런 식의 UPC 번호로는 물리적인 서가의 위치를 찾을 수 없다는 점을 상기시켰다. 그들이 말하길, 각 기록물들은 다른 방식으로 진열된다고 했다. CD 타이틀은 주로 오디오 북이며 조그만 규모의 진열장 안에 저자의 성 (last name) 기준으로 정렬되고, DVD 타이틀은 장르나 제목으로 정렬된다고 했다. 마지막으로 잡지의 경우는 제목과 볼륨, 그리고 이슈번호로 분류되고 있었다. ( 책은 아까 얘기한 것처럼 DDS 번호에 의해 서가에 꽂힌다. )
객체지향적인 설계 경험이 없었기 때문에 처음에 우리는 카탈로그 객체안에 각각의 DVD, CD, 잡지들을 다른 목록으로 나눠 저장하기로 했다. 그런데 그렇게하더라도 어떤 공통적인 속성으로 서가의 물리적인 위치를 나타낼 방법이 없었다. 따라서 상속 (inheritance) 를 사용하기로 했다. 우리는 재빨리 기존 UML 다이어그램을 변경했다.
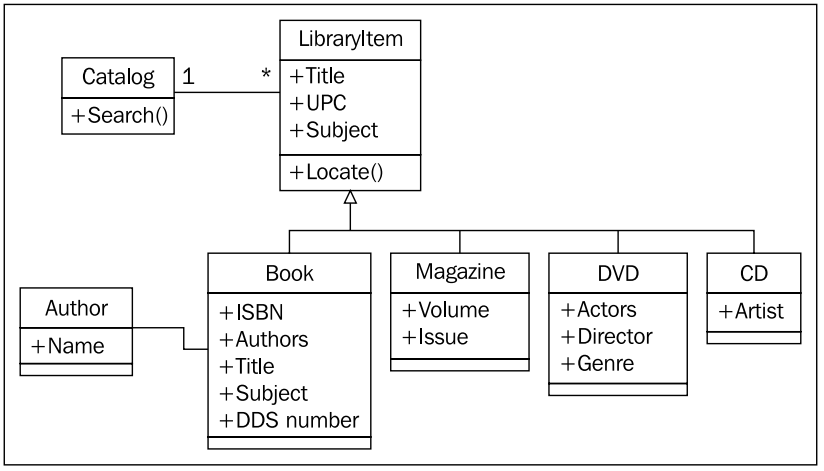
사서들은 우리가 스케치해간 다이어그램의 개괄적인 내용을 이해했다. 하지만 locate 라는 메쏘드에 대해서는 쉽게 이해하지 못하는 듯 했다. 우리는 이해를 돕기 위해 ‘bunnies’ 라는 단어로 검색을 하는 경우를 예로 들어 설명했다. 사용자는 먼저 카탈로그에 검색 요청을 보낸다. 카탈로그 시스템은 내부 아이템 ( LibraryItem 객체 ) 에 질의하여 ‘bunnies’ 라는 책이나 DVD를 찾아준다. 이 부분에서 카탈로그는 그것이 책인지 DVD인지, CD인지 아니면 잡지인지 신경쓰지 않는다. 모든 아이템 객체에 대해서 동등하다. 하지만 사용자는 당장 어떻게 하면 물리적인 위치를 찾을 수 있는지 궁금해 한다. 그렇다. 카탈로그 시스템이 단지 검색된 제목들의 목록만을 반환하는 것은 중요한 것을 놓친 셈이다. 책 ( book ) 의 locate 메쏘드는 DDS 번호를 반환할 것이다. DVD는 장르와 제목에 의해 정렬된다. 사용자는 DVD 섹션으로 가서 해당 장르의 섹션를 찾고 특정 제목으로 정렬된 DVD를 찾게 된다.
설명한 것처럼, 우리는 시퀀스 다이어그램 ( sequence diagram ) 을 그려서 다양한 객체들이 어떻게 통신하는지 설명하였다.
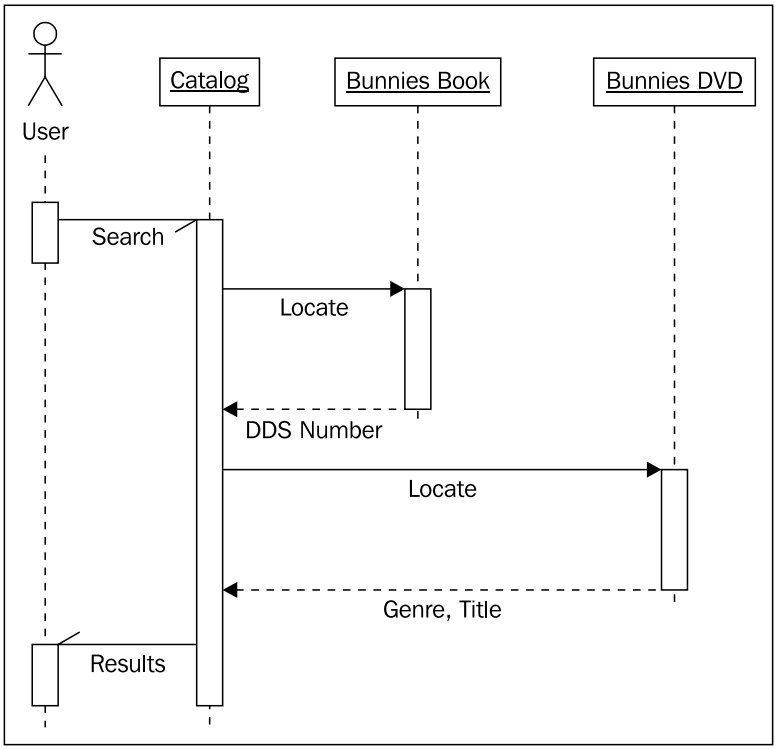
클래스 다이어그램이 클래스들 간의 관계를 표현하는 것이라면, 시퀀스 다이어그램은 객체들 간 주고 받는 메시지들의 흐름을 나타낸다. 각 객체에서 출발한 점선은 해당 객체의 생애주기 ( lifeline ) 을 말한다. 점선 사이에 있는 사각형 박스는 객체의 실제 처리를 나타낸다. (객체가 아무 일도 하지 않으면 사각형 박스를 그리지 않는다. ) 각 생애주기선 사이의 수평 화살표는 특정 메시지를 의미한다. 실선 화살표는 호출되는 메쏘드를 의미하고, 점선 화살표는 해당 메쏘드의 반환 값을 의미한다. 반쪽짜리 화살표 머리는 비동기적 메시지 ( asynchronous messages ) 를 의미한다. 비동기 메시지의 경우 일반적으로 첫 번 째 객체가 다른 객체의 메쏘드를 호출하면 즉각적으로 리턴이 이뤄지는 것을 말한다. 어떤 처리과정을 거쳐서 호출된 객체는 다시 첫번째 객체의 메쏘드를 통해서 값을 전달한다. 이것이 일반적인 메쏘드 호출에서 값을 바로 반환하는 것과 다른 점이다.
시퀀스 다이어그램 ( sequence diagram ) 역시, 다른 UML 다이어그램과 마찬가지로, 필요할 때 사용하면 된다. 이런 다이어그램을 꼭 그려야만하는 어떤 이유는 없다. 객체 간의 연속된 상호작용을 표현해야 할 때는 시퀀스 다이어그램이 굉장히 유용한 툴이 된다.
아직까지 우리가 설계한 내용은 정리가 덜 되어있다. DVD 타이틀에서의 연기자와 CD 타이틀에서의 연주자는 사람 (people) 객체에 속하는 것들이다. 하지만 그것들이 책 (book) 에서의 저자 (author) 와 다르게 대접받고 있다. 사서는 또한 대부분의 CD 들은 오디오 북이라서 연주자 (artist) 대신 저자 (author) 를 써야 맞다고 했다.
어떻게 하면 어떤 제목에 대해 다른 종류의 사람 (people) 유형을 처리할 수 있을까? 한 가지 명확해 보이는 방법은 이름과 관련된 다른 정보들을 갖는 사람 (person) 클래스를 만들고, 이 클래스의 종속 클래스인 연주자 (artist), 저자 (author), 연기자 (actor) 클래스들을 만드는 것이다. 하지만 과연 상속 ( inheritance ) 개념을 굳이 여기 집어 넣어야 하는가? 단지, 검색과 카탈로깅 하기 위한 목적이라면 연기와 글 쓰기를 다른 두 종류의 행위로 간주할 필요는 없을 것이다. 만약 경제 분석을 위한 시뮬레이션 시스템이었다면, 연기자와 저자 클래스 각각에 calculate_income, perform_job 이라는 메쏘드를 집어 넣어야 겠지만, 카탈로그를 위한 목적이라면, 그저 아이템에 기여한 사람이 누구인지 정도만 알고 있으면 충분할 것 같다. 모든 아이템들 ( book, DVD, CD, magazine ) 이 한 명 혹은 둘 이상의 기여자 (contributor) 를 갖고 있으므로, 저자 (author) 와의 관련성 (relationship) 을 책 (book) 보다 상위 클래스로 이동시켜야 한다:
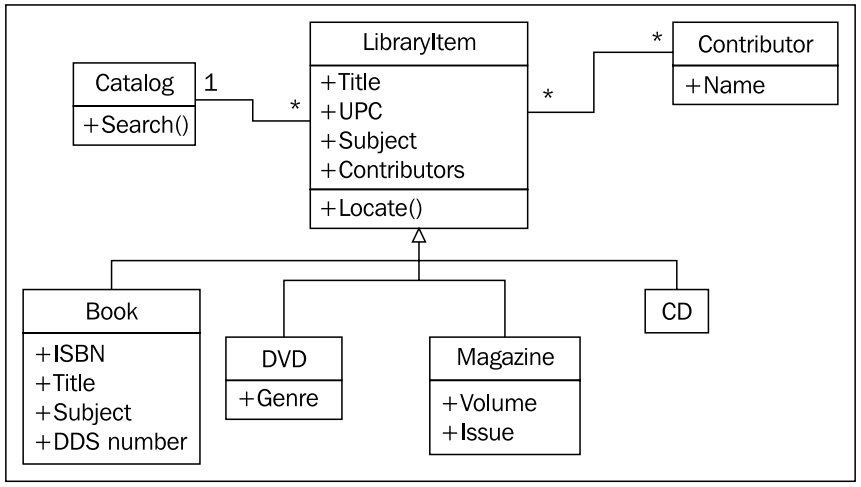
기여자 (contributor)/아이템 (libraryitem) 사이의 다중도 ( multiplicity ) 는 다대다 관계이다. 관계선 양쪽 끝의 * 가 의미하는 것이 복수개를 뜻하기 때문이다. 어떤 하나의 도서관 아이템은 하나 이상의 기여자 (contributor) 를 가질 수 있고, 여러 저자들이 많은 책을 쓸 수 있다.
약간의 수정으로 모델링이 좀더 깔끔해지고 단순해졌지만, 중요한 정보 하나를 읽어 버렸다. 이 관계에서 누가 기여 했는지는 알수 있지만 어떻게 기여했는가는 알 수 없다. DVD 를 예로 들어보면, 기여자가 감독인가 연기자인가? 그들이 오디오 북을 썼는가 아니면 나래이션을 했는가?
contributor_type 이라는 속성을 기여자 (contributor) 클래스에 추가한다면 좋을 것이다. 하지만 이것 또한 여러 역할을 한 사람의 경우 맞지 않는다. 예를 들어 책의 저자이기도 하면서 영화를 감독한 경우라면?
한 가지 방편으로 모든 아이템의 종속 클래스, 즉 책, DVD, CD, 잡지 마다 우리가 필요한 정보를 넣는 것이다. 이 때 발생하는 문제는 우아하게 설계하려 했던 다형성 ( polymorphism ) 에 심각한 손상을 입는 다는 것이다. 만약 각 아이템 별로 기여자 목록을 갖길 바란다면, 각 아이템별로 특정한 속성들을 찾아야만 할 것이다. 책이면 저자, DVD 면 연기자 처럼 말이다. 이런 부담을 조금 덜어내고자 아이템 (libraryitem) 클래스에 GetContributor() 메쏘드를 넣고 종속 클래스에서 이를 오버라이드 ( override ) 하게 하면 될 것이다. 그렇게 되면 카탈로그는 각 객체별로 알고 있어야 할 속성이 무엇있지 몰라도 된다.
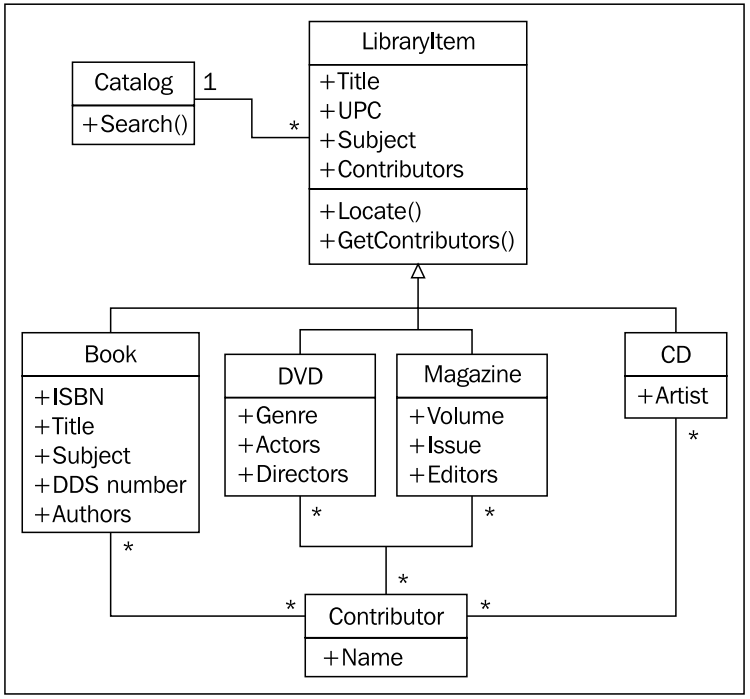
위 다이어그램을 한번 응시해 보자! 아마도 뭔가 잘못한한 것만 같다. 설계가 지나치게 방대해 졌고 깨지기 쉬운 구조이다. 필요한 것들을 모두 넣은것 같은데 이 구조를 유지하고 확장하기는 어려워 보인다. 관계들이 지나치게 많고, 하나의 클래스를 수정했을 때 영향받는 클래스들도 많아 보인다. 이런걸 스파게티 또는 미트볼 같다고 말한다.
상속 ( inheritance )를 한 가지 옵션으로 생각해 둔 적이 있다. 기여자 (contributor) 가 아이템 클래스에 직접적으로 붙어 있었던 이전 composition 기반의 다이어그램으로 돌아가서 생각해 보자. 기여자의 역할 (type of contributor) 을 규정지을 새로운 객체에 관계를 이어주면 된다. 이것은 객체지향 설계에서 중요한 단계이다. 최초 요구사항 대로 모델링하기 보다는 다른 객체를 의도적으로 도와주는 ( support ) 클래스를 설계에 집어 넣을 것이다. 우리는 실재의 객체 대신 시스템 속에만 존재하는 가상의 객체를 활용하여 설계를 리팩토링( refactoring; 코드 재구성 ) 할 것이다. 리팩토링 ( refactoring ) 은 프로그램이나 설계 유지보수의 핵심적인 단계이다. 리팩토링의 목적은 코드를 이동하거나 중복을 없애고 복잡한 관계를 보다 단순하고 우아한 설계로 변경하여 설계를 향상 시키는 것이다.
이 새로운 클래스는 기여자 (contributor) 와 기여 역할 (contributor type) 이라는 추가 속성으로 구성되어 있다. 특정 아이템은 여러 기여자를 갖고 있고, 한 명의 기여자는 여러 아이템에 기여할 수 있다. 아래 다이어그램은 이런 설계를 잘 표현해 준다.
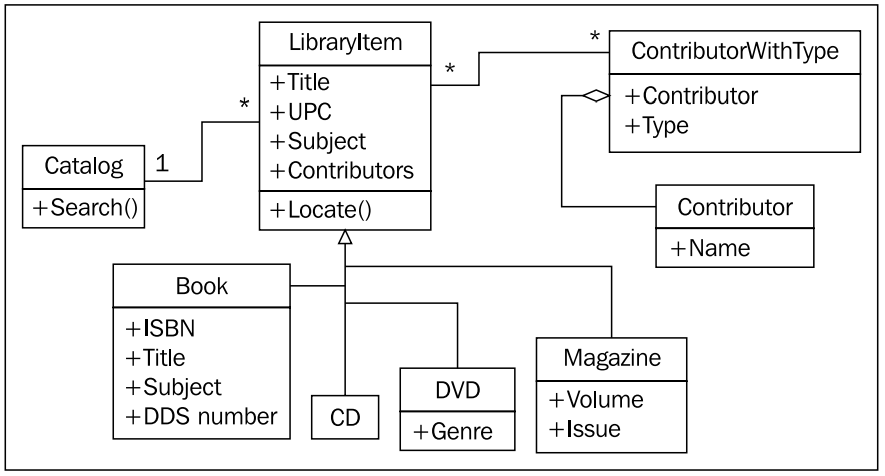
첫 인상은 이 합성 관계 ( composition relationship ) 다이어그램은 상속 기반 관계 다이어그램 보다 조금은 덜 자연스러워 보인다. 하지만 새로운 기여 역할이 추가 되었을 때, 새로운 클래스의 추가가 필요없다는 장점이 있다. 특수화 ( specialization ) 는 종속 클래스에 새로운 속성 (attribute) 또는 행위 (behavior) 를 만들거나 추가하여 부모 클래스와 차별성을 두는 것이다. 단지 서로 다른 종류의 객체들을 구분하기 위해서 다량의 빈 클래스들을 ( empty classes ) 만드는 것은 멍청한 짓이다. ( 자바나 다른 ‘모든 것은 객체다’ 를 신봉하는 프로그래머들 입장에서는 납득하기 어려운 얘기일 순 있다. ) 만약 상속 ( inheritance ) 버전의 다이어그램을 본다면, 다량의 종속 클래스들이 아무 것도 하지 않는다는 것을 알게 될 것이다.
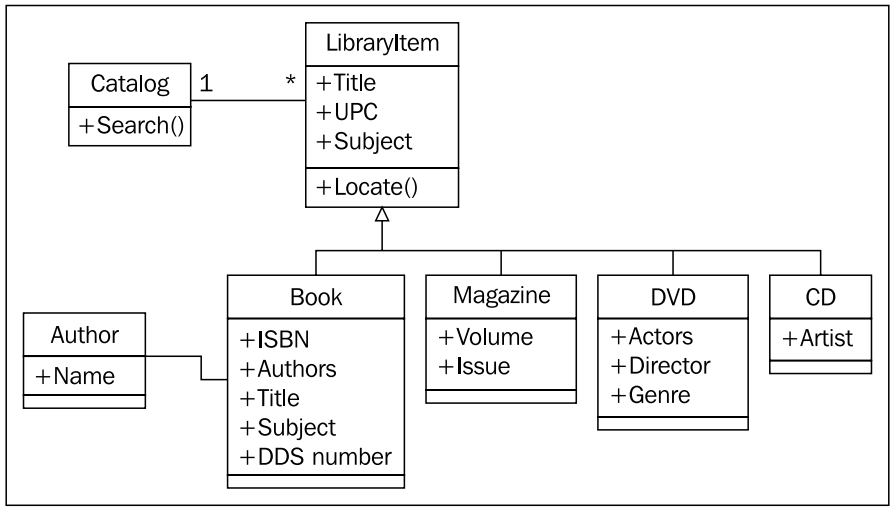
때때로 객체지향 방법론을 사용하지 말아야하는 때를 아는 것이 중요하다. 상속을 사용하지 않아야 할 때를 보여주는 이 예제는 객체는 단지 도구이며, 법칙이 아니라는 것을 상기 시켜준다.