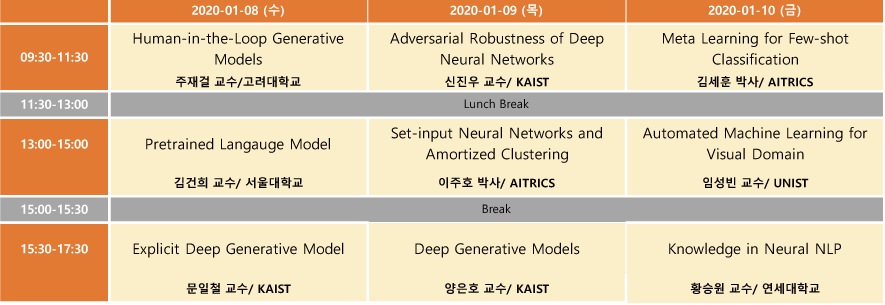
2020 인공지능학회 동계강좌를 신청하여 2020.1.8 ~ 1.10 3일 동안 다녀왔다. 총 9분의 연사가 나오셨는데, 프로그램 일정은 다음과 같다.
전체를 묶어서 하나의 포스트로 작성하려고 했는데, 주제마다 내용이 꽤 많을거 같아, 한 강좌씩 시리즈로 묶어서 작성하게 되었다. 마지막 아홉 번째 포스트에서는 연세대 황승원 교수님의 “Knowledge in Neural NLP” 강연 내용을 다룬다.
- Basic of NLP
- Neural NLP in one hour (This section is based on the lecture below)
- http://videolectures.net/DLRLsummerschool2018_neubig_language_understanding/
- Main categories of NLP tasks
- Language modeling : P(text)
- “Does this sound like good English/French/…?”
- Text classification : P(label | text)
- “Is this review a positive review?”
- “What topic does this article belong to?”
- Sequence transduction :P(text | text)
- “How do you say this in Japanese?”
- “How do you respond to this comment?”
- Language Analysis : P(labels/tree/graph | text)
- “Is this word a person, place or thing?”
- “What is the syntactic structure of this sentence?”
- “What is the latent meaning of this sentence?”
- Language modeling : P(text)
- Language Model
- Phenomena to handle
- Morphology / Syntax / Semantics / Discourse / Pragmatics / Multilinguality, …
- Neural network gives us a flexible tool to handle these
- Phenomena to handle
- Sentence classification
- Sentiment Analysis : very good / good / neutral / bad / very bad
- I hate this movie => “very bad”
- I love this movie => “very good”
- A first Try : Bag of Words (BoW)
- each word has its own 5 elements corresponding to [very good, good, neutral, bad, very bad]
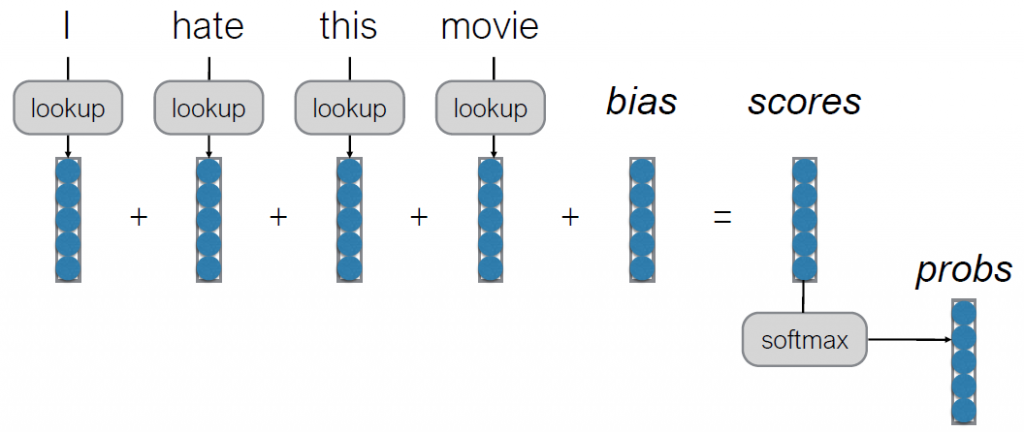
- But there are some problems to extract combination features
- I don’t love this movie.
- Continuous Bag of Words (CBoW)
- each word has its own 5 elements corresponding to [very good, good, neutral, bad, very bad]
- With n-grams
- Allow us to capture combination features in a simple way
- ex) “don’t love”, “not the best”
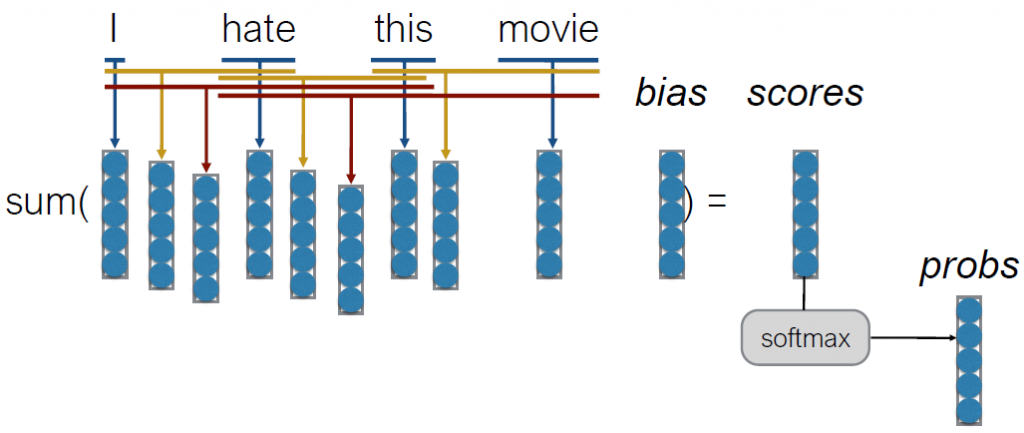
- Problem
- Leads to sparsity : many of the n-grams will never be seen in a training corpus
- No sharing between similar words / n-grams
- books.google.com/ngrams
- Another approaches
- Time Delay Neural Networks
- CNN
- Generally 1D convolution \approx Time Delay Neural Network (TDNN)
- CNN are great for short-distance feature extractors
- Don’t have holistic view of the sentence
- RNN
- To remember Long-distance dependencies
- Weakness
- Indirect passing of information => Made better by LSTM/GRU but not perfect
- Can be slow
- Count-based Model
- Count up the frequency and divide
P_{ML}(x_i|x_{i-n+1}, ..., x_{i-1}) := \dfrac{c(x_{i-n+1}, ..., x_i)}{c(x_{i-n+1}, ..., x_{i-1})} - Add smoothing, to deal with zero counts
P_{ML}(x_i|x_{i-n+1}, ..., x_{i-1}) := \lambda P_{ML}(x_i | x_{i-n+1}, ..., x_{i-1}) + (1-\lambda)P(x_i|x_{1-n+2}, ..., x_{i-1}) - Problems
- Cannot share strength among similar words
- Cannot condition on context with intervening words
- Cannot handle long-distance dependencies
- Count up the frequency and divide
- Featurized Models
- Calculate features of the context
- Based on the features, calculate probabilities
- Linear Models can’t learn feature combinations
- Neural Language Models
- Strength
- Similar output words get similar rows in the softmax matrix
- Similar contexts get similar hidden states
- Word embeddings : Similar input words get similar vectors
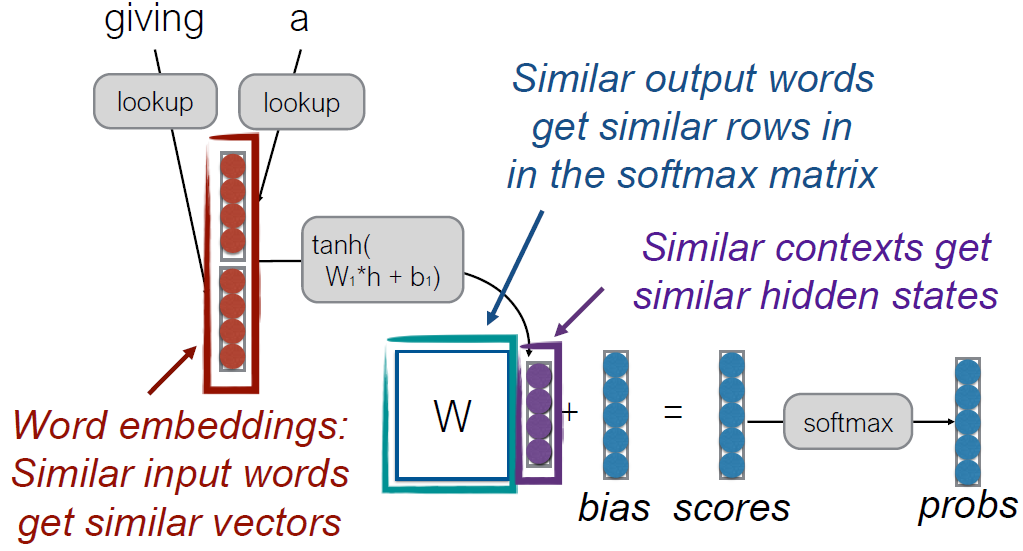
- Strength
- Sentiment Analysis : very good / good / neutral / bad / very bad
- Sequence Transduction
- Conditioned Language Models
- Input X / Output Y (Text) / Task
- Structured Data / NL Description / NL Generation
- English / Japanese / Translation
- Document / Short Description / Summarization
- Utterance / Response / Response Generation
- Image / Test / Image Captioning
- Speech / Transcript / Speech Recognition
- Dialog ( Multi-turn
- Input X / Output Y (Text) / Task
- Attention
- Encode each word in the sentence into a vector
- When decoding, perform a linear combination of these vectors, weighted by “attention weights”
- Use this combination in picking the next word
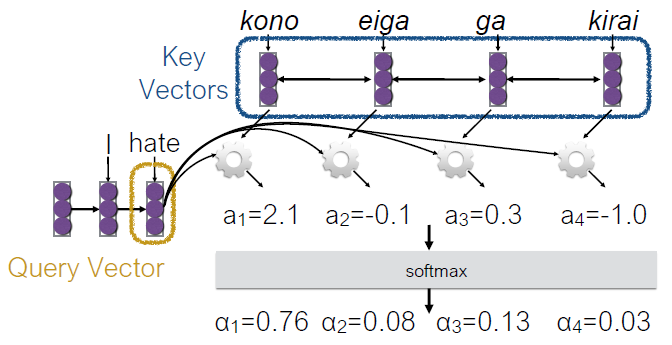
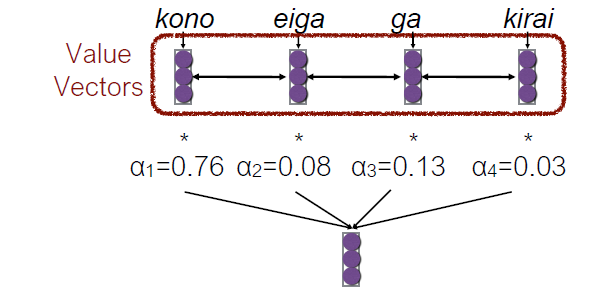
- Conditioned Language Models
- Learn More
- Neural NLP in one hour (This section is based on the lecture below)
- Knowledge in NLP
- NLP examples
- Q & A
- Information Extraction
- Dialogue : Smart Reply, but very limited
- Sentiment Analysis : This is either a research area or prediction area such like stock price prediction.
- Entity2Topic Module
- By using Entity Linking, one can insert additional information to improve the performance of abstractive summarization models
- Tips before attention
- Remove ambiguity on information
- Eliminate unnecessary information
- Emphasize more important information
- Sentence Classification
- Problem
- Context sparsity : Features should be extracted from a single sentence
- Domain-dependent Solution : This is not easy.
- Look Neighboring sentences
- Refer other reviews
- Seek Latent topics
- Translation as CS contexts
- Always available
- Ambiguity Resolution
- Extensible Context
- Better Classifying in WordVec
- Problem
- Beyond BERT
- The BERT is powerful, but has limitations on self-training
- Human reporting bias ( trivial things can not be reported)
- Weak for Adversarial examples
- Considerations
- Use additional information on Entities
- Knowledge Encoding
- Knowledge Distillation
- Augmentation
- Paraphrase
- Supervision of Attention
- The BERT is powerful, but has limitations on self-training
- References
- Learning with Limited Data for Multilingual Reading Comprehension, EMNLP 2019
- MICRON: Multigranular Interaction for Contextualizing Representation in Non-factoid Question Answering, EMNLP 2019
- Soft Representation Learning for Sparse Transfer, ACL 2019
- Explanatory and Actionable Debugging for Machine Learning: A TableQA Demonstration, SIGIR 2019 (demo)
- Counterfactual Attention Supervision, ICDM 2019
- Categorical Metadata Representation for Customized Text Classification, TACL 2019
- Cold-Start Aware User and Product Attention for Sentiment Classification, ACL 2018
- Translations as Additional Contexts for Sentence Classification, IJCAI 2018
- Entity Commonsense Representation for Neural Abstractive Summarization, NAACL 2018
- NLP examples