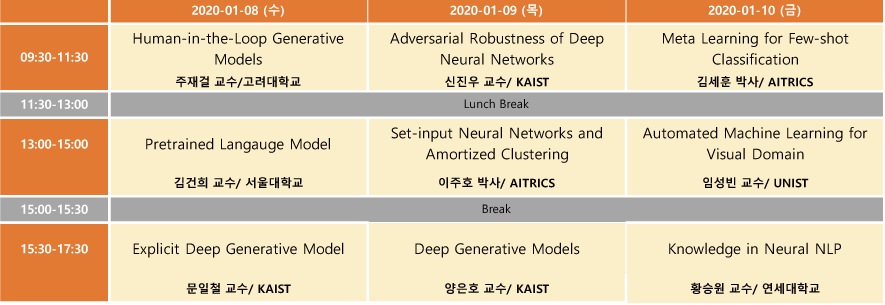
2020 인공지능학회 동계강좌를 신청하여 2020.1.8 ~ 1.10 3일 동안 다녀왔다. 총 9분의 연사가 나오셨는데, 프로그램 일정은 다음과 같다.
전체를 묶어서 하나의 포스트로 작성하려고 했는데, 주제마다 내용이 꽤 많을거 같아, 한 강좌씩 시리즈로 묶어서 작성하게 되었다. 일곱 번째 포스트에서는 AITrics 김세훈 박사님의 “Meta Learning for Few-shot Classification” 강연 내용을 다룬다.
- Introduction : 소수샷 분류 정의와 메타 학습 접근법
- 소수샷 분류 (Few-shot Classification) 문제 정의
- 적은 수의 레이블 정보만으로 generalization 성능을 높이려는 시도
- 과적합 방지 위해 단순 선형 모델 혹은 unlabled 데이터 활용가능
- 메타 학습 (Meta-Learning)
- 학습하는 방법을 배우는 학습 패러다임
- 일반 Learning : \theta = arg \min_{\theta} \sum_{(x,y) \in D} Loss(x,y;\theta)
- 메타 Learning : \theta = arg \min_{\theta} E_{T \sim P(T)} [ \sum_{(x,y) \in D_T} Loss(x,y;\theta) ]
- N -way K-shot 문제
- N은 범주의 수, K는 범주별 서포트 (Train) 데이터의 수 (참조 : 카카오 브레인)
- 개념도
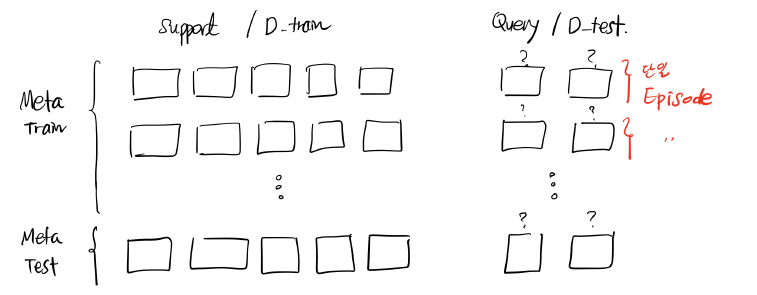
- 메타 Train 과 Test 시점의 그룹을 다르게 설정
Meta Train : A class 그룹에서 생성한 소수샷 Task
↓
Meta Test : B class 그룹에서 생성한 소수샷 Task - 데이터 셋 : Omniglot, https://github.com/brendenlake/omniglot
- 학습하는 방법을 배우는 학습 패러다임
- 소수샷 분류 (Few-shot Classification) 문제 정의
- Metric-based Approaches
- Matching Network
- Vinyals et al, Matching Networks for One Shot Learning, NeuraIPS 2016
- 미분 가능한 최근접 분류기를 통해 소수샷 문제를 해결
- 목적식 :
arg \max_{\theta} E_{E \sim T} [ E_{(D_{train}, D_{test}) \sim E} [\sum_{(\hat{x}, \hat{y}) \in D_{test}} \log P (\hat{y} | \hat{x}, D_{train})]] - Bidirectional LSTM 사용
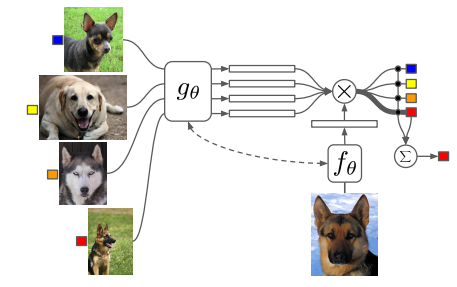
- Permutation Invariant 하진 않으나 되도록 Insensitive 하도록 노력.
- Prototypical Network
- Snell et al, Prototypical Networks for Few-shot Learning, NeurIPS 2017
- Bidirectional LSTM 대신 Prototype 으로 Set 표현식을 정의
- Transductive 소수샷 학습
- T. Joachims, Transductive Inference for Text Classi cation using Support Vector Machines, ICML 1999
- Liu et al, Learning to Propagate Labels: Transductive Propagation Network for Few-shot Learning, ICLR 2019
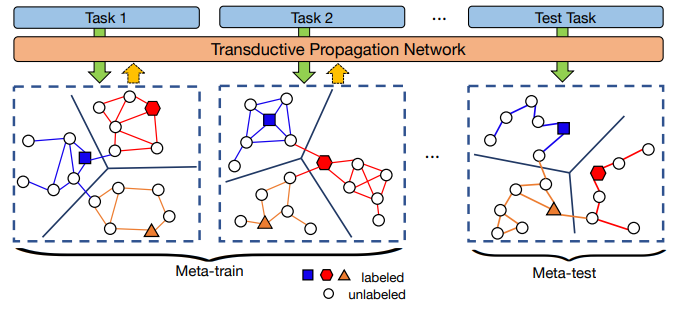
- 트랜스덕티브 학습은 테스트 데이터의 분포를 고려하여 모델의 과적합을 방지
- 데이터의 매니폴드를 활용하여 인접 레이블을 전파
- Kim et al, Walking on Minimax Paths for k-NN Search, AAAI 2013
- Zhu et al, Learning from Labeled and Unlabeled Data with Label Propagation, Tech. Report 2002
- Matching Network
- Gradient-based Approaches
- MAML (Model-Agnostic Meta-Learning)
- Finn et al, Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks, ICML 2017
- Meta Test 시점에 D_train 정보를 활용하여 모델을 미세 조정
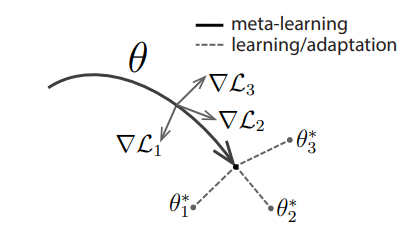
- 여러 번 업데이트를 할 때 메타 파라미터 학습
\theta_0 = \theta_{meta}
\theta_1 = \theta_0 - \alpha \nabla_{\theta} L(\theta)_{|\theta_0}
\theta_2 = \theta_1 - \alpha \nabla_{\theta} L(\theta)_{|\theta_1}
\dots
\theta_k = \theta_{k-1} - \alpha \nabla_{\theta} L(\theta)_{|\theta_{k-1}} - Gradient 계산
\dfrac{\partial \theta_{j+1}}{\partial \theta_j}^T = \dfrac{\partial (\theta_j - \alpha \nabla_{\theta}L(\theta)_{|\theta_j})}{\partial \theta_j}= I - \alpha \nabla^2 L(\theta)_{| \theta_j} - \theta 를 업데이트할 때, Hessian 을 구해야 하기 때문에 상당히 느림
- Mask-Transform Network
- Y. Lee and S. Choi, Gradient-Based Meta-Learning with Learned Layerwise Metric and Subspace, ICML 2018
- MAML 의 inner gradient loop 에서 전체 네트워크의 일부분만 학습하도록 설계
- LEO (Meta-Learning with Latent Embedding Optimization)
- Rusu et al, Meta-Learning with Latent Embedding Optimization, ICLR 2019
- Mask-Transform Network 과 유사하게 네트워크의 일부 파라미터만 adaption 함.
- Encoding : 많은 수의 Neural Network 파라미터를 2N 차원 벡터로 변환
- Decoding : Latent code 에서 Softmax Classifier 의 파라미터를 복원
- MAML (Model-Agnostic Meta-Learning)
- Set-Input Approaches
- Overview
- 이전 포스트인 AITrics 이주호 박사 강의 내용 참조.
- Neural Statistician
- 더 좋은 Set 표현식을 얻고자 확률 모델링 고려
- Variational Inference 통한 Bayesian 학습 기반의 Set 표현식 알고리즘
- Dropout 의 파라미터를 데이터로부터 학습하고 싶은 경우
- Kingma et al, Variational Dropout and the Local Reparameterization Trick, NeurIPS 2015
- 변분추론 Examples
- Neklyudov et al, Structured Bayesian Pruning via Log-Normal Multiplicative Noise, NeurIPS 2017
- Lee et al, Adaptive Network Sparsification with Dependent Variational Beta-Bernoulli Dropout, ArXiv 2018
- Overview
- 현재 소수샷 분류 실험의 한계
- Meta Train 과 Meta Test Task 모두 같은 데이터셋에서 생성
- Omniglot 으로 학습한 메타 학습기가 CIFAR-100 에서 생성한 Task 를 잘 해결할 수 있는가?
- 여러 데이터셋에서 만든 메타 학습기를 조합하여 문제 해결
- Park et al, TAEML: Task-Adaptive Ensemble of Meta-Learners, NeurIPS 2018
- 여러 데이터셋에서 만든 메타 학습기를 조합하여 문제 해결
- Omniglot 으로 학습한 메타 학습기가 CIFAR-100 에서 생성한 Task 를 잘 해결할 수 있는가?
- Meta Train 과 Meta Test Task 모두 같은 데이터셋에서 생성
- 최신 주요 논문들
- Kim et al, Edge-labeling Graph Neural Network for Few-shot Learning, CVPR 2019
- Lee et al, Set Transformer, ICML 2019
- Finn et al, Probabilistic Model-Agnostic Meta-Learning, NeurIPS 2018
- Kim et al, Bayesian Model-Agnostic Meta-Learning, NeurIPS 2018
- Gordon et al, Meta-Learning Probabilistic Inference For Prediction, ICLR 2019