
From 27 OCT to 2 NOV, ICCV 2019 was held in Coex Seoul. [official webpage link]: http://iccv2019.thecvf.com/
I summarized attended programs below.
SUN 27 OCT Tutorial. “Interpretable Machine Learning for Computer Vision“
[link] : https://interpretablevision.github.io/
1. Andrea Vedaldi: Understanding Models via Visualization and Attribution
– Generating conic examples
> Inversion vs activation maximization
> The importance of the prior
> Aesthetic vs diagnostic
– Attribution
> (Modified) gradient backpropagation
> Excitation and relevance backpropagation
> Meaningful perturbation analysis
> Understanding via approximating models
2. Bolei Zhou: Understanding Latent Semantics in GANs
– Interpretable units in intermediate layers
> Online demo: ganpaint.io
– Semantics in the latent space
> Latent Space: Natural lighting // Indoor lighting, Wooden // Non-wooden, Cloudy // Non-Cloudy
– Inversion of real images
> reconstructed image
> GAN’s don’t like a lot of things!
– Future directions
> Invertible Generative Models
> Invertible Network + VAEs
> Steerability of GANs: Zoom, Brightness, Rotate2D //3D, Shift X //Y

3. Alan L. Yuille: Deep Compositional Networks
– Deep Nets are hard to interpret and have unusual failure modes.
In particular: they are sensitive to occlusion and context.
Part 1: Visual Concepts: Internal Representations
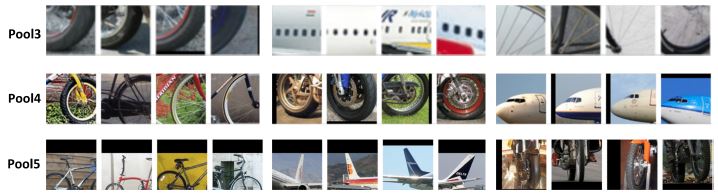

Part 2: Compositional Nets for Object Classification
MON 28 OCT Tutorial. “Visual Recognition for Images, Video, and 3D”
[link]: https://alexander-kirillov.github.io/tutorials/visual-recognition-iccv19/
1. Saining Xie : On Connectivity for Representation Learning
1) Representation
2) Connectivity
– Revisiting Neural Network as ‘connectivity’ perspective
NAS : Neural Architecture Search
– Main forcus is on search space
– Implementations are substantially different
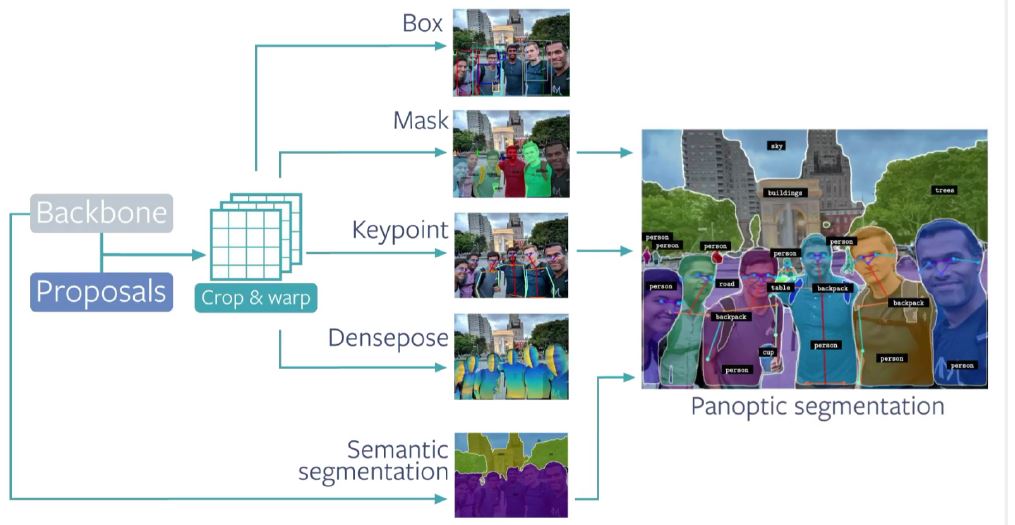
2. Ross Girshick : Object Detection and Instance Segmentation
“The Generalized R-CNN Framework for object detection”
– Object Detection with Bounding Box
> what?
> where?
– Object Detection with Semantic Mask
> Is this picture correct ?
– Beyond Boxes and Masks:
> Human Keypoints
> Human Surfaces
> Panoptic Segmentation
> 3D shape
R-CNN families
1) R-CNN
2) Generalized R-CNN
3) Fast R-CNN
4) Faster R-CNN
5) FPN (Feature Pyramid Network)
6) Mask R-CNN

<Writing Good Object-Detection Papers>
– single forcused idea
– do not say unrelated idea
– show the simplest version of your idea
– ablations : one table, one message
– support all of your claims
– beware of speed / accuracy claims
– implement all methods in one codebase
– avoid big tables of historical comparisons
– check generalization to bigger models -> longer training time
3. Yuxin Wu: Detectron 2
4. Justin Johnson: Mesh Reconstruction in the Wild
– mesh R-CNN = Hybrid Technique (Voxel + Mesh)

5. Nikhila Ravi: Torch3d & Mesh R-CNN
6. Christoph Feichtenhofer: Recognition in Video
7. Haoqi Fan: Video Recognition Codebase
TUE 29 OCT Main Conference.
ICCV 2019 Awards
Best paper award (Marr prize)
- “SinGAN: Learning a Generative Model from a Single Natural Image” by Tamar Rott Shaham, Tali Dekel, Tomer Michaeli

Best Student Paper Award
- “PLMP – Point-Line Minimal Problems in Complete Multi-View Visibility” by Timothy Duff, Kathlén Kohn, Anton Leykin, Tomas Pajdla
Best Paper Honorable Mentions
- “Asynchronous Single-Photon 3D Imaging” by Anant Gupta, Atul Ingle, Mohit Gupta
- “Specifying Object Attributes and Relations in Interactive Scene Generation” by Oron Ashual, Lior Wolf
Best Paper Nominations
- “Larger Norm More Transferable: An Adaptive Feature Norm Approach for Unsupervised Domain Adaptation” by Ruijia Xu, Guanbin Li, Jihan Yang, Liang Lin
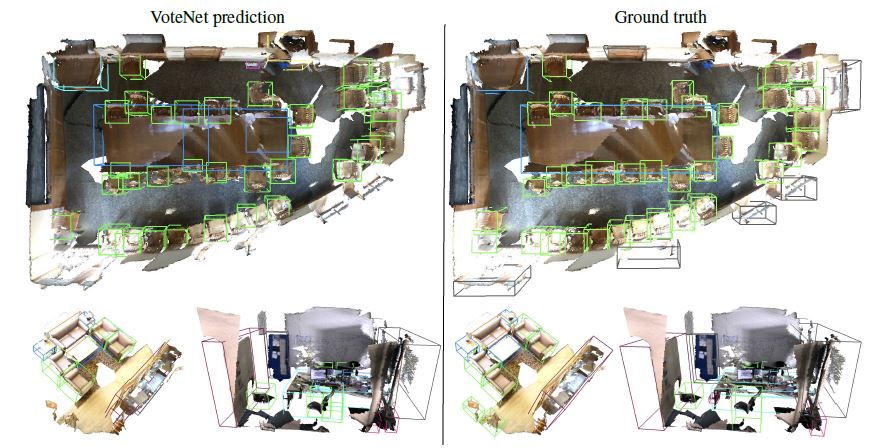
- “Deep Hough Voting for 3D Object Detection in Point Clouds” by Charles R. Qi, Or Litany, Kaiming He, Leonidas Guibas
- “Unsupervised Deep Learning for Structured Shape Matching” by Jean-Michel Roufosse, Abhishek Sharma, Maks Ovsjanikov
- “Gated2Depth: Real-time Dense Lidar from Gated Images” by Tobias Gruber, Frank Julca-Aguilar, Mario Bijelic, Felix Heide
- “Local Aggregation for Unsupervised Learning of Visual Embeddings” by Chengxu Zhuang, Alex Zhai, Daniel Yamins
- “Habitat: A Platform for Embodied AI Research” by Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana M. Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra
- “Robust Change Captioning” by Dong Huk Park, Trevor Darrell, Anna Rohrbach
Morning
11. NLNL: Negative Learning for Noisy Labels, Youngdong Kim
Afternoon
1. Exploring Randomly Wired Neural Networks for Image Recognition, Saining Xie
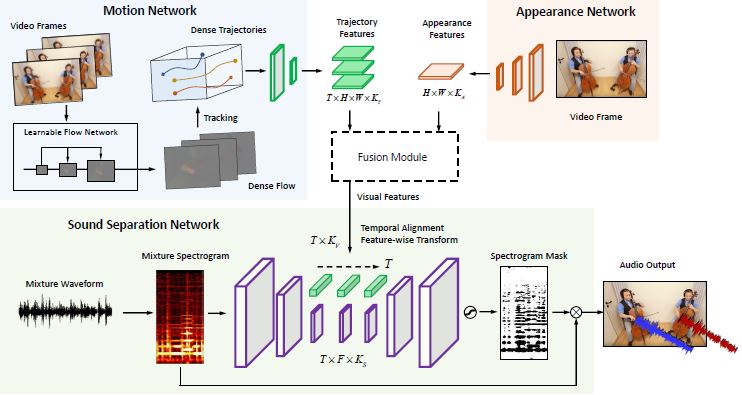
46. The Sound of Motions, Hang Zhao
THU 31 OCT Main Conference.
Afternoon
6. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features, Sangdoo Yun

9. Scale-Aware Trident Networks for Object Detection, Yanghao Li
10. Object-Aware Instance Labeling for Weakly Supervised Object Detection, Satoshi Kosugi
11. Generative Modeling for Small-Data Object Detection, Lanlan Liu
13. Self-Training and Adversarial Background Regularization for Unsuperivsed Domain Adaptive One-Stage Object Detection, Seunghyeon Kim
18. Bayesian Loss for Crowd Count Estimation With Point Supervision, Zhiheng Ma
Industry Booth
Artisense
– Two cameras and one IM sensor (for supplement) to generate 3D point cloud
– from two 2D images it can generate depth information
– 2D image segmentation + depth information can generate segmented 3D point cloud
– it can draw observer’s trajectories and segmented 3D points from the seen
– upload/download segmented point clouds to/from clouds

FRI 1 NOV Main Conference.
Morning
13. A Neural Network for Detailed Human Depth Estimation From a Single Image, Sicong Tang
14. DenseRaC : Joint 3D Pose and Shape Estimation by Dense Render-and-Compare, Yuanlu Xu
16. Extreme View Synthesis, Inchang Choi
17. View Indenpendent Generative Adversarial Network for Novel View Synthesis, Xiaogang Xu
Afternoon
1. YOLACT: Real-Time Instance Segmentation, Daniel Bolya
3. Multi-Class Part Parsing With Joint Boundary-Semantic Awareness
6. ShapeMask: Learning to Segment Novel Objects by Refining Shape Priors, Weicheng Kuo
13. Deep Hough Voting for 3D Ojbect Detection in Point Clouds, Charles R. Qi
29. S2GAN: Share Aging Factors Across Ages and Share Aging Trends Among individuals, Zhenliang He
30. PuppetGAN: Cross-Domain Image Manipulation by Demonstration, Ben Usman
SAT 2 NOV Workshop & Tutorial.
Workshop. “Computer Vision for Fashion, Art and Design” (11:00~12:00)
[link]: https://sites.google.com/view/cvcreative
1. Luba Elliott: AI in Contemporary Art
– www.elluba.com // Luba.elliott@gmail.com
aionline.com
computervisionart.com
Daniel Ambrosi
Gene Kogan
Sofia Crespo
Mario Klingeman
Scott Eaton
Libby Heaney : Deep Face
AI Told Me
Roman Lipski

Anna Rider
Egor Kraft
Coralie Vogelaar
Constant Dallaart
Eva Nowak
Tom white
Harm van den Dorpel
Ben Snell
Pierre Huyghe
Ai-Da Robot
Tutorial. “Visual Learning with Limited Labeled Data”
[link]: https://sites.google.com/view/learning-with-limited-data
1. Kevin Swersky: Meta-learning and Metric Learning Algorithms
2. Leonid Karlinsky: Data Augmentation/Hallucination-based Techniques
3. Judy Hoffman: Domain Adaptation and Transfer Learning – Part 1