흔하디 흔한 제목이고 많은 소개 자료가 있어 굳이 블로그에 포스트할 필요가 있나 싶었지만, 최근 보게 된 책에서 내용을 잘 설명해 주어서 책의 흐름을 따라가면서 소개해 보고자 한다. 내가 읽은 책은 『Python3 Object Oriented Programming – Harness the power of Python 3 objects, Dusty Phillips, PACKT』 이다. 이 책은 객체지향 프로그래밍 (OOP) 관점도 훌륭하게 소개시켜 주고 있지만, Python 3 에 꼭 필요한 내용들을 다루고 있어서 정말 추천하고 싶은 책이다.
이 포스트에서는 Python 3 문법을 이야기 하지는 않는다. 기회가 된다면 그건 다른 포스트를 통해서 진행될 것이다.
자! 그럼 본격적으로 객체지향 프로그래밍에 대해서 이야기 해 보자.
많은 객체지향 프로그래밍을 다룬 책들을 보면, 지나치게 예제에 매몰되어서 “도형-사각형, 원, 삼각형” 류의 예시나 “새-오리, 독수리, 타조” 이런 류의 비현실적인 예시들로 꽉 들어차 버린다. 실재적으로 객체지향 프로그로그래밍을 어떤 식으로 접근하며 어떤 과정으로 개념들이 도입되는지를 설명하지 않기 때문에 그저 이론으로 전락해 버리곤 한다.
그럼 객체지향 프로그래밍은 도대체 무엇인가?
객체지향 (Object-Oriented) 은 말 그대로 우리 주변에 있는 모든 것들을 사물(object) 로 바라보는데에 있다. 사물이란 감지할 수 있고 느낄 수 있는 어떤 것들을 말한다. 소프트웨어 개발에서도 이 정의는 크게 다르지 않은데, 단지 만질 수 있고 건드릴 수 있는 것들만이 아니라 어떤 것을 할 수 있고, 또 그것들을 움직일 수 있는 대상이라고 할 수 있다. 짧게 말하면 객체(object) 는 데이터(data) 와 그것에 연관된 행동(behavior) 들의 집합이라고 할 수 있다. 따라서 객체지향의 의미는 이 객체들을 모델링하는 방향으로의 기능구현이라고 할 수 있겠다.
객체지향 소프트웨어 개발은 크게 3단계로 나눠지는데 객체지향 분석 (analysis), 객체지향 설계 (design), 객체지향 프로그래밍 (programming) 이다. 객체지향 분석에서는 어떤 것을 만들어야 하는지 (what needs to be done) 파악하는 단계이다. 이들 요구사항을 바탕으로 구체적인 개발(구현) 스펙을 정하는 단계가 객체지향 설계단계이다. 설계가 끝나면, 이를 프로그래밍 언어로 변환하는 객체지향 프로그래밍 단계가 된다.
<객체와 클래스들; Objects and classes>
사과와 오렌지는 컴퓨터 프로그래밍에서 모델링 되는 경우는 거의 없지만, 우리가 간단한 과일 창고에 사용될 응용프로그램을 개발한다고 가정해 보자. 사과는 들통(Barrel) 에 오렌지는 소쿠리(Basket) 에 보관한다고 생각해 보자. 이미 4가지의 객체들을 얻었다. 사과, 나무통, 오렌지, 소쿠리. 객체지향 모델링에서는 이런 객체들을 클래스(class) 라고 일컸는다. 그래서 4가지의 클래스(class) 들을 정의할 수 있다. 4가지의 클래스들 사이의 연관성은 UML (Unified Modeling Language)의 클래스 다이어그램(class diagram) 으로 표현 할 수 있다.
다음은 4가지 클래스 사이의 연관관계를 나타낸 클래스 다이어그램이다.
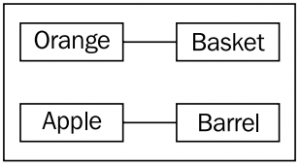
위 다이어그램은 단순하게 오렌지는 Basket 에 사과는 Barrel(들통)과 연관있다는 것을 알려준다. 연관 (Association) 이야 말로 그 클래스(class) 사이의 연관성을 나타내는 가장 대표적인 방식이다.
UML 은 소프트웨어 개발자와 관리자들 사이에서 보편적인 의사소통 방식중의 하나이다. UML 문법에 관한 자료들이 많이 나와 있지만 이런 것들을 상세하게 알고 굳이 튜토리얼을 따라해볼 필요는 없다. 단지 직관적으로 다른 사람들과 의사소통하는데 도움이 된다면 그저 좋을 뿐이다. 클래스 다이어그램의 경우, 객체(object) 들은 사각형 Box 에 표현하고 이들 사이의 연관이 있다면 선으로 연결시켜 표현하면 된다. 많은 다이어그램들이 UML 안에 있지만 클래스 다이어그램 (class diagram), 시퀀스 다이어그램 (sequence diagram), 유스케이스 다이어그램 (use diagram) 정도만 사용하더라도 크게 유용하다. ( UML 에 관해서는 구글링을 해 보면 많은 내용을 찾을 수 있다. UML 에 대해 관한 책을 추천하라고 하면, 『UML 실전에서는 이것만 쓴다 JAVA 프로그래머를 위한 UML, 로버트 C. 마틴, 인사이트』이 책을 추천하고 싶다.)
위 예시에서 사과-들통, 오렌지-소쿠리 연관 관계는 파악되었다. 하지만 사과가 들통에 담기고, 오렌지가 소쿠리에 담긴다는 정보와 사과(들이) 들통 하나에 담기고, 오렌지(들이) 소쿠리에 담긴다는 수량 관계정보를 추가할 수 있다. UML 에 장점은 이러한 추가적인 정보들을 부가적으로 기술할 수 있다는데에 있다. 클래스 다이어그램을 다시 그려보자.
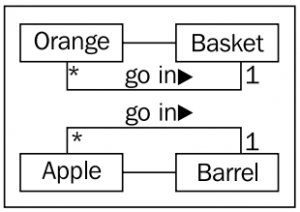
‘담긴다’ 는 정보는 ‘go in’ 으로 표현하였고, 수량 관계는 다대일; ‘*’ 은 복수개, ‘1’ 은 하나를 의미, 로 표현되었다.
<객체 속성과 행동의 기술; Specifying attributes and behaviors>
한 가지 알아두어야 할 용어가 있다. 바로 객체 (object) 와는 다른 객체 (instance) 이다. 우리말로 object 와 instance 모두 객체로 번역할 수 있기 때문에 혼동을 피하기 위해서 인스턴스(instance) 라고 하는 표현이 더 쉽겠다. 인스턴스는 클래스의 현실화다. 흔히 붕어빵 틀을 클래스(class)라고 하면 그 틀에서 찍어낸 붕어빵이 인스턴스(instance) 가 된다. 정리해서 말해보면, 사물을 관념적으로 나타낸 표현이 클래스(class) 이고 실재하는 존재가 인스턴스(instance) 가 된다. 객체(object) 와 혼동을 피하기 위해, 객체 인스턴스 (object instance) 라고도 한다. ( object 를 ‘사물’ 로 번역하면 의미 전달이 좀 더 명확해 지겠지만, 그렇게 되면 object-oriented 가 ‘사물지향’ 이 되기 때문에 object 는 객체로 나둬야 한다;;)
대게 객체지향 프로그래밍 코드상에서 인스턴스는 ‘new’ 라는 키워드를 사용하여 생성된다. 하나의 클래스를 통해 여러 인스턴스들이 생성되기 때문에 붕어빵 처럼 찍어낸다는 표현을 쓴다. 예) a_car = new Car()
데이터(data) 는 객체(object) 를 기술한다.
데이터는 객체의 특성을 나타낸다. 탁자에 오렌지 3개가 있다고 할 때, 각각의 오렌지의 무게는 다를 것이다. 그러면 ‘무게’라는 속성(attribute) 은 오렌지를 기술하는데 사용되고 모델링 될 수 있다. 속성(attribute) 은 종종 프로퍼티 (property) 라고 지칭되기도 한다. 우리가 만들 과일 창고 응용 프로그램을 다시 생각해 보자. 농부는 아마 오렌지들이 어떤 과수원에서 왔는지 궁금할 것이다. 그리고 언제 수확했는지, 무게는 얼마나 나타는지도 궁금할 것이다. 그리고 오렌지들이 담긴 소쿠리는 어디 선반에 있는지 위치도 알아야 한다. 사과의 경우에는 사과의 색깔과 무게, 들통의 크기등의 정보를 알아야 한다. 이런 속성(attribute) 들을 추가하여 우리 클래스 다이어그램을 확장시켜 보자.
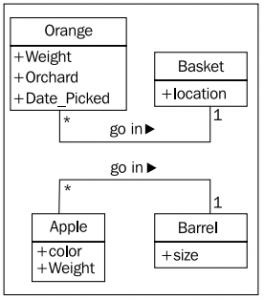
설계의 상세함의 정도에 따라 클래스 다이어그램에 표현하는 정보의 양은 차이가 날 수 있다. 위 다이어그램보다 단순하게 표현할 수도 있고, 더 많은 정보를 넣을 수도 있다. 그것은 순전히 같이 일하는 개발자와 관리자들의 선택에 달려 있다. (개인의 성향 차이에서 기인하는 부분도 있다. 어떤 개발자들은 이런 그림을 그리는 것보다 말로써 설명하는 것을 좋아하고 어떤 개발자들은 잘 설계된 도면만 던져주고 말을 아끼기도 한다. 하지만 말로 설명하는 것 보다 이렇게 클래스 다이어그램을 그려가서 이를 바탕으로 의사소통하는 것이 훨씬 시간을 절약하는 길임은 분명하다. 그러나 UML 을 위한 UML 혹은 산출물을 위한 산출물을 만드는 것은 아무런 의미가 없다.)
위의 클래스 다이어그램에서 속성이 어떤 데이터 형식 (data type) 을 가지는지 좀 더 명확히 기술해 줄 수 있다. 그리고 연관 (association) 을 양쪽 각각의 포함된 객체로 나타내 줄 수 있다. 이렇게 장식을 좀 더 하면 아래와 같은 다이어 그램을 얻는다.
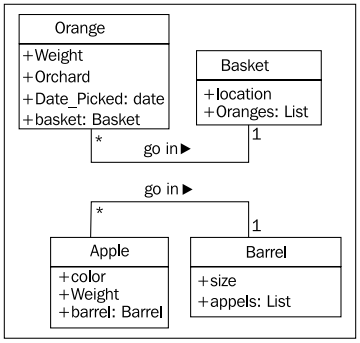
행동 (behavior) 은 행위 (action) 이다.
데이터(data) 가 객체에 대한 기술이라면, 행동 (behavior) 는 객체에 발생하거나 수행할 행위 (action) 이다. 이들 행동들을 메쏘드(method) 라고 지칭한다. 프로그래밍에서는 메쏘드는 함수(function) 이라고도 한다. 이들 메쏘드들은 파라미터 (parameter) 들을 받아서 어떤 값 (value) 을 반환한다. 파라미터는 메쏘드에 입력되어야 하는 객체들의 목록이고, 반환 값은 작업의 결과물이다.
과일 창고 프로그램에서 오렌지가 수확되는 (pick) 행위가 있을 수 있다. 오렌지를 따면 소쿠리에 담긴다. 따라서 소쿠리에 담긴 오렌지의 수량이 하나 증가한다. 따라서 이런 pick 함수는 소쿠리(basket) 을 입력으로 받는다. 한편, 농부가 오렌지를 짜면 (squeeze), 주스가 되어 일정량의 오렌지 주스를 얻는다. 또 소쿠리 (basket) 은 판매되어 과일 창고의 수입이 증가한다. 이런 일련의 행위들을 모델링하여 클래스 다이어그램을 업데이트 해 보자.
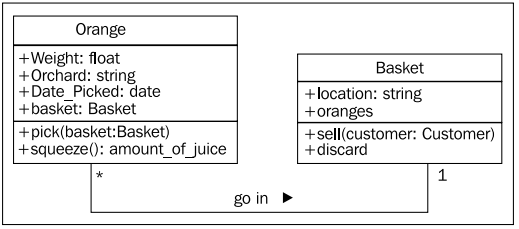
이렇게 객체의 속성들을 추가하고 행위들을 추가하면 객체들 간의 상호작용이 생겨난다. 각 객체들은 어떤 클래스의 멤버가 되고, 이들 클래스는 어떤 형태의 데이터들이 취급되는지 규정하고, 어떤 메쏘드들을 호출하는지 정한다. 같은 클래스 내부의 서로 다른 데이터들은 다른 상태를 가지고 어떤 메쏘들에 다르게 반응한다. 객체지향 분석과 객체지향 설계는 어떤 객체들이 존재하고 어떻게 서로 상호작용하는지 밝혀내는 작업이다. (Object-oriented analysis and design is all about figuring out what those objects are and how they should interact.) 이어서 이들 상호작용을 좀 더 간단하고 직관적으로 만드는 방법들을 살펴보자.
<디테일의 숨김과 공개 인터페이스 생성; Hiding details and creating the public interface>
어떤 객체(object) 를 객체지향적(object-oriented) 으로 설계하는 가장 중요한 목적은 공개 인터페이스 (public interface) 를 선정하는 일이다. 여기서 인터페이스란 하나의 객체가 다른 객체와 상호작용하는 속성(attribute) 와 메쏘드 (method) 들의 집합체를 의미한다. 이 인터페이스는 해당 객체 내부의 작동을 알 필요는 없으며, 종종 이 내부적인 상황에 접근하지 못하기도 한다. 좋은 예가 있다. 텔레비전과 리모콘의 예시이다. 우리는 리모콘을 텔레비전 객체를 조종하기 위한 인터페이스로 생각할 수 있다. 리모콘을 사용하여 텔레비전을 조종할 때, 텔레비전이 안테나로부터 어떤 시그널을 받는지, 케이블 연결이나 위성접시 같은 것은 모른다. 볼륨을 조정할 때, 전송되는 전기적 신호나 이들 신호가 스피커나 헤드폰으로 출력되는 메카니즘에 대해서 관심이 없다. 만약 이런 내부 매커니즘을 알기 위해서 TV를 분해해 버린다면, 제품 보증을 포기하는 셈이다.
이런 실재 구현이나 기능적인 상세함을 숨기는 것을 정보 숨김 (information hiding) 이라고 한다. 또는 은닉 (encapsulation) 이라고 부르기도 한다. 은닉은 쉽게 말하면 캡슐에 싸서 감추는 것인데, 타임캡슐에 어떤 정보들을 넣고서 땅에 묻는다는 의미로 생각하면 된다. 엄밀한 의미에서 은닉은 정보 숨김과는 다를 수 있으나 이것을 굳이 구분하는 것은 큰 의미를 갖기는 못한다. 우리는 이 둘을 같은 뜻으로 사용할 것이다. 다만 Python 의 관점에서 볼 때, 정보 은닉은 그렇게 중요하게 다뤄지지 않는다.
공개 인터페이스는 정말 중요하다. 정말 조심스럽게 설계해야 하는데, 왜냐하면 나중에는 변경하기가 어렵기 때문이다. 변경하려면 이것을 호출 (calling) 하는 클라이언트 부분이 영향을 받기 때문이다. 프로그램 상에서 객체가 현실 객체와 다르다는 점을 명심하자. 자동차를 모델링 한다고 해서 실재의 자동차에 비해 복잡도는 훨씬 덜할 것이다. 이런 모델들은 실재 개념의 추상화이기 때문이다.
추상화 (Abstraction) 은 또 다른 객체지향의 buzzword 이다. 추상화는 특정 작업을 수행하는데 가장 적합하도록 상세함의 정도 (level of detail) 를 정하는 일이다. 다른 말로 하면 내부 디테일로부터 공개 인터페이스를 추출해 내는 일련의 과정을 의미한다. 예를들며, 자동차 운전자는 핸들과 가속패달, 브레이크와 상호작용한다. 내부 모터와 조향장치 브레이크 시스템은 운전자에게 관심의 대상이 아니다. 반면에 자동차 정비공은 다른 추상화 수준에서 작업하는데, 엔진을 고치고 브레이크를 조이고 하는 등 말이다. 이들 운전자와 정비공이 자동차에 대해 서로 다른 추상화 수준을 갖고 있는 것은 다음 그림을 보면 좀 더 명확해 진다.
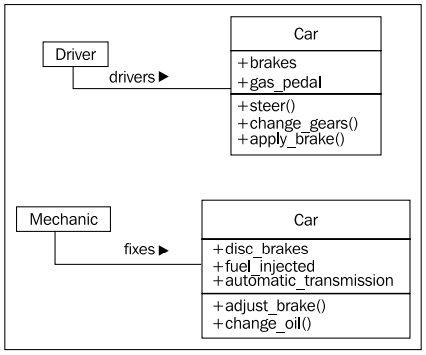
다시 한번 요약하자면, 추상화 (abstraction) 은 공개 인터페이스와 내부 인터페이스를 분리하여 정보 은닉을 하기 위한 일련의 프로세스이다.
여러 객체들과 상호작용하는 모델을 이해하기 쉽게 만들기 위해서는 조그만 디테일들에 신경써야 한다. 메쏘드와 속성들에 센스있는 명칭을 부여하자. 시스템을 분석할 때, 사물(객체)는 대게 명사로 표현되고 메쏘드 (method) 들은 동사로 표현한다. 속성(attribute) 은 종종 형용사가 선택될 수 있다. 미래에 언젠가 유용할 지 모를 객체나 행위를 미리 모델링하지 말자. 시스템이 정확히 수행해야 할 작업들을 모델링하고, 설계는 알맞은 추상화 수준을 견지해야 한다. 우리의 설계는 미래 요구사항의 변경에 항상 준비되어 있어야 한다.
인터페이스를 설계할 때는 객체 내부에 침투해서 해당 객체가 보호 받아야 할 프라이버시가 무엇인지 생각해 봐야 한다. 다른 객체들이 함부로 이들 객체에 접근하지 못하도록 해야 한다.