2020 인공지능학회 동계강좌를 신청하여 2020.1.8 ~ 1.10 3일 동안 다녀왔다. 총 9분의 연사가 나오셨는데, 프로그램 일정은 다음과 같다.
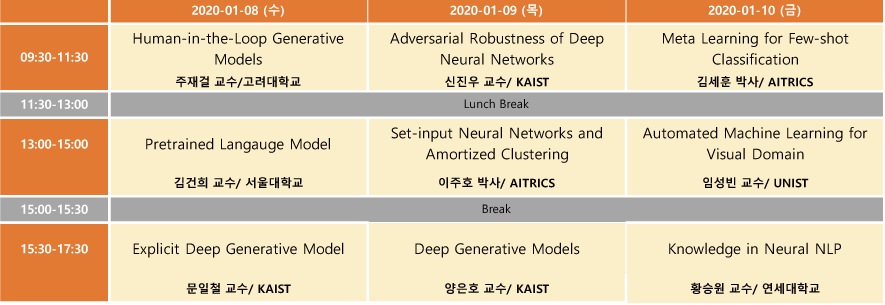
전체를 묶어서 하나의 포스트로 작성하려고 했는데, 주제마다 내용이 꽤 될거 같아, 한 강좌씩 시리즈로 묶어서 작성하게 되었다. 두 번째 포스트에서는 서울대학교 김건희 교수님의 “Pretrained Language Model” 강연 내용을 다룬다.
- 자연어 처리에서는 사용된 Context 에 따라 단어의 의미가 달라진다.
- 강의 주제 : How to get contextualized word representation ?
- Language Model
- Word Sequence Likelihood
- p(x_{1:T})=p(x_1) \prod^T_{t=1}p(x_t|x_{1:t-1})
- Importance of Language Models
- Play a key role in several NLP tasks, ex) speech recognition, machine translation
- Language Model Pretrain 의 목적
- Downstream task 성능 향상
- Word Sequence Likelihood
- ELMO
- Peters et al, Deep contextualized word representations, NAACL 2018
- Word representation from RNN based bidirectional language model
- How to use ELMO embeddings?
- 기존 word embedding 에 concatenation 하여 downstream task 변형 없이 사용
- BERT
- Devlin et al, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
- RNN 기반 Language Model 의 문제점
- Hard to parallelize efficiently
- Back propagation through sequence -> gradient vanishing / explosion
- Transmitting local/global information through single vector -> Difficult to model long-term dependency
- Autoregressive Language Model 단점
- Unidirectional
- Self-Attention
- 일반적인 attention 쿼리 절차
- Similarity finding with query
- Softmax
- Weighted value sum (soft attention)
- self-attention
- key = query : query 가 단어 단체 key 값
- self-attention 은 모든 위치의 단어들을 연결 시킨다.
- 일반적인 attention 쿼리 절차
- BERT : Bidirectional Encoder Representations from Transformers
- Use Transformer as a Backbone Language Model Network
- Pretrain with two losses :
- Masked Language Model
- Next Sentence Prediction (NSP)
- Transformer
- Vaswani et al, Attention is All you Need, NIPS 2017
- Multi-head Attention
- Comparison with ELMo
- ELMo : Autoregressive LM
- BERT : Masked LM
- Pretraining
- Masked LM : bidirectional conditioning
- Mask some percentage (15%) of the input tokens at random
- Predict the original value of the masked words
- Mismatch between pre-training (빈 칸 채우기) and fine-tuning (Downstream Task)
- Next Sentence Prediction
- 두 문장 사이의 관계를 나타내는데 필요한 Loss, ex) IsNext, NotNext
- Input representation
- Token embedding
- Segment embedding
- Position embedding
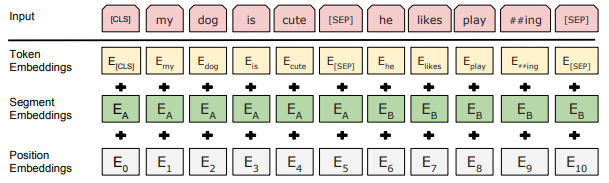
- Use BERT embeddings
- Pretrain on the Corpus
- Finetune for downstream tasks with few task-specific layers on top of BERT
- Masked LM : bidirectional conditioning
- Performance boost
- GLUE (General Language Understanding Evaluation) : a collection of diverse language understanding tasks
- SQuAD 1.1 / SQuAD 2.0
- SQuAD : The Stanford Question Answering Dataset
- SWAG : Situations with Adversarial Generations
- Effect of the model size
- BERT is a really BIG model
- Fine-tuned on a single Cloud TPU with 64GB of RAM
- Not reproducible from conventional GPUs with 12GB – 16GB of RAM due to small batch sizes
- RoBERTa and ALBERT
- RoBERTa
- Robustly optimized BERT approach, proposed by Facebook
- Lie et al, RoBERTa: A Robustly Optimized BERT Pretraining Approach, Arxiv 2019
- Characteristics
- Dynamic Masking
- Remove NSP loss
- Training with large batches
- Text encoding
- 10x more training time and data
- ALBERT
- A Lite BERT
- Lan et al, ALBERT: A Lite BERT for Self-supervised Learning of Language Representations, ICLR 2020
- Characteristics
- Factorization embedding parameterization
- Cross-Layer parameter sharing
- Inter-sentence coherence loss
- RoBERTa