이전 포스트 에서 Naive Bayes Classifier 의 알고리즘에 대해서 알아보았다. 여기서는 Spam Mail Filter 와 NewsGroup 분류에 사용된 Naive Bayes 에 대해서 알아보자. 인터넷에도 굉장히 많은 예제들을 쉽게 확인 할 수 있다.
나는 “Python Machine Learning By Example” 이라는 책에서 다룬 스팸(Spam) 메일 필터링 예제를 설명하려고 한다.
2. Naive Bayes Classifier Applications
1) Spam mail filtering
Spam 분류해야 할 email 수 백, 수 천개가 있다고 치자. 각각의 email 은 길고 짧건 많은 수의 단어(word) 들로 이루어져 있다.
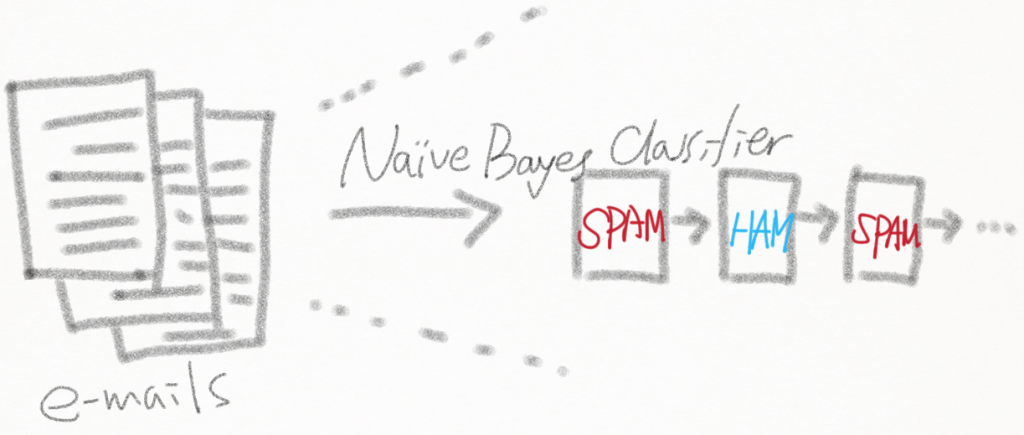
우리의 목적은 각각의 email 이 어떤 단어들로 이루어져 있는지 검사해 보고, 확률상 Spam 일 가능성이 높은지 아닌지에 따라 mail 을 분류하면 된다. Spam 인 경우 확률적으로 자주 등장하는 단어가 있고 아닐 경우(Ham) 자주 등장하는 단어가 있을 것이다.
각각의 email 들에 대해 Spam 일 경우 ‘1’ 이라는 label 을 부여하고, 아닐 경우 ‘0’ 이라는 label 을 부여한다.
우리 예제에서는 모두 5171개의 email 을 대상으로 label 을 분류하였다. email 을 전부 배열 요소에 할당한 뒤에는 nltk 모듈을 사용하여 의미있는 단어들만을 남기기 위한 전처리 작업을 수행한다.

데이터를 사용할 준비가 모두 끝났다면 CounterVectorizer 를 활용하여 단어 Feature 들을 형렬 형태로 추출해 낸다. 이 부분을 좀더 직관적으로 이해할 필요가 있기에 CounterVectorizer 를 사용해 추출된 형렬은 다음과 같은 형태를 지닌다.
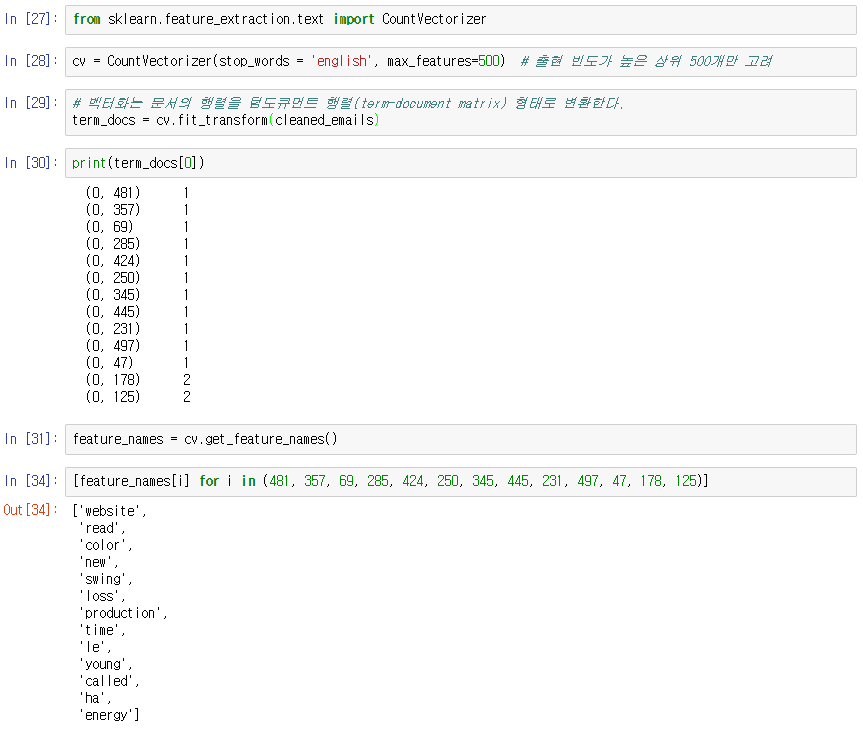
준비가 끝났으면, 사전 확률(prior) 와 가능도(likelihood) 함수를 작성한 뒤에는 주어진 데이터 셋을 대입하여 사전 확률과 가능도를 계산한다. (여기서는 단순히 계산한다고 얘기했지만 단순한 형태의 ‘학습’으로 볼 수 있다.) 준비된 계산 결과를 테스트 해 보기 위해 샘플 데이터를 대입하여 Spam 을 잘 걸러내는지 확인해 본다.
이 과정들을 정리해 보면 다음과 같다.
1. 이메일을 모두 읽어들여서 레이블 변수와 메일 변수에 담는다.
- spam = 1, 정상 = 0
- 5172개의 Email Document List 와 분류결과 Label List 확보
2. 원본 테스트 데이터를 전처리하고 정제
- 숫자와 구두점 표기 제거
- 사람 이름 제거(옵션)
- 불용어 (stopword) 제거
- 표제어 원형 복원
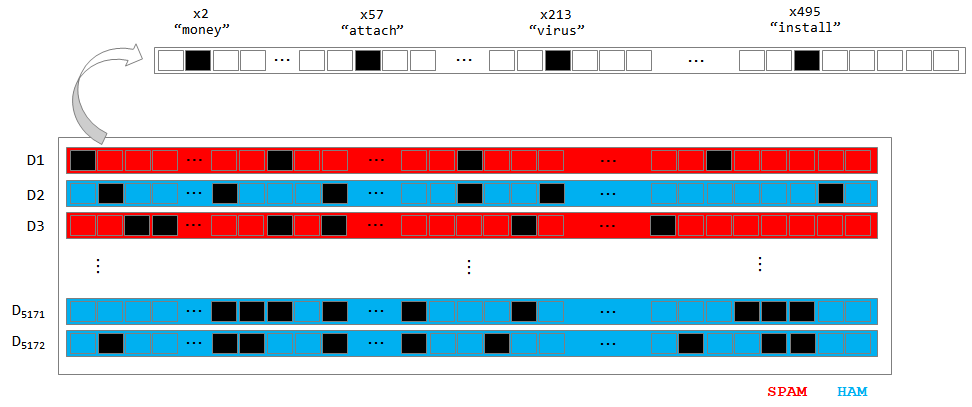
3. CounterVectorizer 를 활용한 행렬화
- 정제된 텍스트 데이터에서 단어 출현 빈도 피처 추출
- term_docs(_train) 의 도식화
4. 사전 확률 (Prior) 계산
- n = the number of documents, y ∈ {1, 0}, where 1 = SPAM, 0 = HAM
- 사전 확률 P(y) = \dfrac {count(y)}{n}
5. 가능도(likelihood) 계산
- P(x_j|y) = \dfrac {\sum_{j =1}^{D} count(x_j)\cdot I(Y=y)}{ \sum_{y} {\sum_{j =1}^{D} count(x_j)\cdot I(Y=y)}}, j = 1, ..., D
- log P(y|X)\propto log(P(y) \prod_{j=1}^{D} P(x_j|y)^{x_j})
[참고 : https://en.wikipedia.org/wiki/Naive_Bayes_classifier]
6. 테스팅;신규 샘플 데이터의 사후 확률을 계산
코드 전체는 Github 를 참조하길 바란다.