이번 포스트는 추정(Estimation) 의 일곱 번째 포스트로 표본 크기 선택 (Selecting the Sample Size) 을 다룬다. 내용은『Mathematical Statistics with Applications, Sixth Edition, DUXBURY , Dennis D. Wackerly / William Mendenhall / Richard L. Scheaffer』 를 참고했다.
7. 표본 크기 선택 (Selecting the Sample Size)
어떤 실험을 설계하는 것은 필수적으로 정보를 양을 구매하는 계획과 같다. 다른 상품과 마찬가지로, 정보를 획득하는 비용은 데이터들이 얻어진 방식에 따라서 달라지게 된다. 어떤 측정의 경우, 관심있는 파라미터에 대한 많은 양의 정보를 갖는다. 다른 경우엔 더 적거나 거의 얻지 못하는 경우도 있다. 연구는, 과학적이든 아니든, 정보를 획득하는것이다. 명확한것은 최소한의 비용으로 정보를 얻을 수 있는 방법을 찾고자 해야 한다는 것이다.
표본 추출의 절차 – 대게는 “실험적 설계 (experimental design) ” 이라고 불리는 – 는 단일 측정 당 정보의 양에 영향을 미친다. 이런 절차 (표본의 크기 ‘n’ 과 같은) 가 단일 표본의 의미있는 정보의 총량을 좌우한다. 이런 측면에서 우리는 가장 간단한 표본 추출의 과정에 알아보려고 한다 : 상대적으로 큰 모 집단으로부터의 랜덤 표본 추출. 주된 관심을 표본의 크기 n 을 선택하는데 놓아보자.
실험자는 표본의 크기를 결정하는 문제를 해결하기 전에는 제대로 된 실험 설계를 수행할 수 없다. 정말로, 통계학자들이 가장 많이 받는 질문중에 하나는: “얼마나 많은 측정을 표본에 포함시켜야 하나요?” 이다. 불행하게도, 통계학자들도 실험자들이 얻고자하는 정보의 양을 알기 전에는 이 질문에 대한 답을 정확히 내기 어렵다. 특별히 추정에 관련하여서는 실험자가 얼마나 정확하게 추정하고자 하는지에 따라서이다. 실험자는 추정의 오차 범위 (bound on the error of estimation) 를 한정함으로써 충족하고자 하는 정확도를 인지할 수 있다.
예를들어, 우리가 어떤 화합물의 일별 평균 수율 \mu 를 추정하고자 한다. 우리는 추정의 오차가 95%의 확률로 5톤 보다 작았으면 한다. 반복된 표본 추출과정에서 표본 평균의 대략 95% 정도가 \mu 에 대한 2\sigma_{\bar{Y}} 에 속하기 때문에, 우리는 2\sigma_{\bar{Y}} 를 5톤과 동치관계로 놓을 수 있다. (아래 그림 참조) 그러면,
\dfrac{2\sigma}{\sqrt{n}}=5.0
n 에 대해서 풀어내면
n=\dfrac{4\sigma^2}{25}
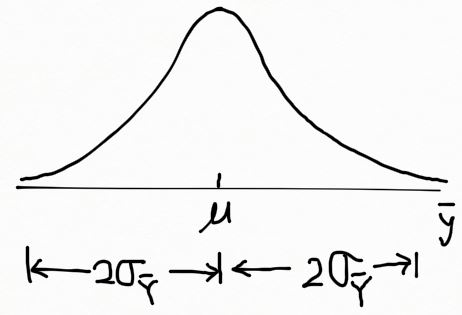
우리는 모 집단의 표준편차 \sigma 를 알기 전까진 정확한 n 값을 얻을 수 없다. 이것은 정확히 우리가 원하는 바인데, 추정량 \bar{Y} 의 변동량은 표본이 구해진 모집단의 변동에 따라 결정되기 때문이다.
\sigma 값의 정확한 값을 모르는상태에서, 가장 근사적으로 가능한 방법은 추정량 s 를 사용하는 것이다. s 는 이전의 한 표본으로 부터 얻거나 모집단의 측정 값들의 범위(range) 정보로 부터 구할 수 있다. 범위가 근사적으로 4\sigma (실제적인 법칙을 상기시켜 보자) 이기 때문에, 범위의 1/4 을 \sigma 에 대한 근사적인 값으로 생각할 수 있다. 예를 들어, 일별 수율의 범위가 84 톤으로 알려져 있다고 하면, \sigma~\approx~84/4=21 이고,
n = \dfrac{4\sigma^2}{25} \approx \dfrac{(4)(21)^2}{25}=70.56
또는 n = 71 .
실제로우리는 추정의 오차를 5톤 보다 훨씬 작게 가져가고자 한다. 실험적인 법칙에 따르면, 추정의 오차가 \sigma_{\bar{Y}}=2.5 톤 보다 작으면 (1시그마 범위 안) 확률은 대략적으로 0.68이 된다. 확률 값인 0.95나 0.68은 정확한 값은 아닌데, 왜냐하면 \sigma 가 근사되었기 대문이다. 비록 표본 크기를 선택하는 이 방식은 추정의 정확도를 한정시키는 단지 근사적인 방법이다. 하지만 가장 훌륭히 가능한 방법이고 직관적으로 표본 크기를 선택하는 것에 비해서는 더 나은 것이다.
3번째 포스트에 정리된 다(多) 표본 추정의 경우, 표본 크기를 선택하는 방법은 위에서 서술한 것과 동일하다. 실험자는 추정 오차와 관련된 신뢰 수준 (1-α) 에 대해 충족하고자 하는 범위(bound) 를 한정해야 한다. 예를 들어, 파라미터가 \theta 이고, 충족하고자 하는 범위가 B 라고 하면,
z_{\alpha/2}\sigma_{\hat{\theta}}=B
로 동치로 놓을 수 있다. ( P(Z>z_{\alpha/2})=\dfrac{\alpha}{2} )
다음 예제들을 통해서 이 방식에 대해 더 살펴 보도록 하자.
| 예제1.
심리학 실험에서 자극에 대한 반응은 2가지 형태로 나타난다. A 또는 B. 실험자가 어떤 사람이 보일 반응에 대한 확률 p 를 추정하고자 한다. 얼마나 많은 사람을 실험에 포함시켜야 할까? 실험자는 추정의 오차가 90%의 확률로 0.04 보다 작으면 만족한다고 가정하자. 또한 p 값은 0.6 근처의 값이라고 가정하자. |
풀이.
1-\alpha = 0.9 로 한정했으므로, \alpha = 0.1 , \alpha/2 = 0.05 0.05에 해당하는 표준 정규분포상의 upper tail 의 z 값은 z_{\alpha/2} = 1.645 이다.
1.645\sigma_{\hat{p}}=0.04 또는 1.645\sqrt{\dfrac{pq}{n}}=0.04
\hat{p} 의 표준오차가 모르는 값 p 에 의존하므로, n을 근사하는데, 실험자가 추측한 값 p = 0.6 을 대신 사용할 수 있다. 그러면,
1.645\sqrt{\dfrac{(0.6)(0.4)}{n}}=0.04 n = 406
이 예제에서 우리는 p \approx 0.6 이라고 가정했다. 실제 값 p 에 대한 아무런 해답이 없다고 하면 어떻게 해야 할까? \hat{p}=Y/n 의 최대 분산 값은 p = 0.5 에서라는 것을 알고 있다. 만약 우리가 p \approx 0.6 를 모른다면 p = 0.5 를 사용할 수 있다. 그럴 경우 가장 큰 n을 갖게 된다: n = 423. 실제 p 이 어떤 값인지간에, n =423 은 확률 0.9로 p 에 대한 오차 범위 B =0.4 를 만족시키는 충분히 큰 값이다.
| 예제2.
어떤 실험자가 조립을 수행하는 제조 작업자들의 훈련방식들의 효율성을 비교해 보고자 한다. 선발된 작업자들은 동일한 크기의 2개 그룹으로 나누어지고, 첫 번째 그룹은 훈련방식 1을 두번재 그룹은 훈련방식2를 부여 받는다. 훈련 이후에 각 작업자들은 조립 공정을 수행하고 조립 수행시간이 기록된다. 실험자는 두 그룹을 통틀어 작업시간이 8분 정도의 범위를 가질 것이라고 기대한다고 한다. 평균 작업시간의 차이값의 추정은 0.95의 확률로 1분 이내로 정확해야 한다면 얼마나 많은 작업자들을 이 실험에 참여 시켜야 할까? |
풀이.
제조업자는 1-\alpha = 0.95 로 한정했으므로, \alpha = 0.05 , z_{\alpha/2}=z_{0.025} = 1.96 . 1.96\sigma_{(\bar{Y_1}-\bar{Y_2})}=1 로 놓으면,
1.96\sqrt{\dfrac{\sigma^2_1}{n_1}+\dfrac{\sigma^2_2}{n_2}}=1
n_1 과 n_2 를 같게 하고 싶기 때문에, n_1=n_2=n 로 놓을 수 있고,
1.96\sqrt{\dfrac{\sigma^2_1}{n}+\dfrac{\sigma^2_2}{n}}=1
이 된다. 앞에서 언급한 것처럼, 각 방식의 변동량은 근사적으로 같기 때문에, \sigma^2_1 = \sigma^2_2 = \sigma^2 . 범위는 8 이고 근사적으로 4\sigma 와 같으므로
4\sigma \approx 8 또는 \sigma \approx 2
이 값을 대입해서 방정식을 풀어보면,
1.96\sqrt{\dfrac{(2)^2}{n}+\dfrac{(2)^2}{n}}=1
풀어보면, n = 30.73 을 얻는다. 그러므로, 각 그룹은 n = 31 명의 작업자들을 포함해야 한다.