이번 포스트는 가설검정의 여섯 번째 포스트로 가설 검정의 이론에 대한 추가 설명 (Some Comments on the Theory of Hypothesis Testing) 를 다룬다. 내용은『Mathematical Statistics with Applications, Sixth Edition, DUXBURY , Dennis D. Wackerly / William Mendenhall / Richard L. Scheaffer』 를 참고했다.
6. 가설 검정의 이론에 대한 추가 설명 (Some Comments on the Theory of Hypothesis Testing)
앞서 살펴보았지만, 단측 검정 (one-tailed test) 과 양측 검정 (two-tailed test) 을 수행할 수 있다. 선택은 실제적인 문제상황에 의해 결정되며, 실험자가 찾고자 하는 파라미터 θ 의 대립되는 값 (alternative value) 에 따라 정해 진다. 만약 θ ≥ θ0 일 때, 큰 회계 손실을 입었다면 θ0 보다 큰 θ 를 찾는데 집중하면 된다. 따라서 앞서 살펴본 것 처럼 분포 상 우측 꼬리 (upper tail) 에 위치할 때 기각 하면 된다. 한편, 동등하게 θ0 보다 큰 θ 나 작은 θ 를 찾아야 한다면, 양측 검정 (two-tailed test) 를 실시할 것이다.
가설 통계 검정의 이론적 배경은 α, β 의 확률로서 귀무 가설을 채택하거나 기각하는데 명확한 지침을 준다. 하지만 이 이론적인 배경이 모든 실제적인 상황에서 충분한 것은 아니다.
하나의 가설 검정에서, type Ⅰ error 의 확률 α 는 귀무가설에 의해 정해지는 파라미터 값에 따라 달라진다. 우리가 다뤘던 검정 절차에서는 이 확률은 적어도 근사적으로 계산할 수 있었다. 지금까지 언급한 절차들에서 type Ⅱ error 의 확률 β 는 우리가 관심있어하는 파라미터가 특정한 값을 지닐 때만 계산 할 수 있다. 실제적으로 의미있는 값을 선택하는 것은 종종 어려운 일이다. 나아가서 의미있는 대립가설이 규정된다고 하더라도, 실제 β 를 계산하기는 꽤나 성가신 일이다. 의미있는 대립가설의 Spec 을 정하는 (Specification of a meaningful alternative hypothesis) 것은 더 어려운 일일 수 있다.
그렇지만 type Ⅱ error 를 범할 가능성 자체를 무시하려는 것은 아니다. 가설 검정 뒷 부분에서는 실험자에 의해 선택된 type Ⅰ error 의 확률 α 을 고정한 채, 가장 작은 확률 β 를 구하는 방법들을 살펴볼 것이다. 하지만 이런 경우에도 가장 작은 확률 β 는 꽤 큰 값이 될 수 있다.
이런 어려움이 있지만, 통계 검정의 효용 자체가 사라지는 것은 아니다. 단지 이것은 불 충분한 정보를 가지고 귀무 가설을 기각하는 결론에 이르는 것을 주의해야 한다는 것을 상기 시킨다. 만약 실제로 의미있는 (그리고 신뢰할 수 있는) β 값이 계산 되었다면, 그리고 이 β 값이 작다면 귀무가설 H0 를 채택하는데 반론의 여지가 없다. 일반적인 경우에는 이 의미있는 β 값을 구하기가 어려우므로, 우리는 검정 방식을 다음과 같이 수정해야 할 것이다. 검정 통계량 값이 기각역에 속하지 않을 때, 우리는 귀무 가설을 ‘채택한다’ 대신 ‘기각할 수 없다‘ 고 해야 한다. 앞 포스트의 예제1. 에서 귀무가설 H0 : p = 0.5 와 대립가설 Ha : p < 0.5 를 검정하였다. 관측된 통계량 Y 가 기각역에 속할 때, 우리는 귀무가설 H0 를 기각하고 연구 가설 (research hypothesis) 인 John 이 선거에서 질 것이다라는 증거로 내세울 것이다. 그러나 Y 가 기각역에 속하지 않으면서 파라미터 p 를 한정할 수 없을 때, 단지 귀무가설 H0 를 기각할 수 없다. 라고 할 것이다. 결론을 내리기 전에 반드시 추가적인 정보를 조사해야만 한다. 대안적으로 우리는 p-값 (p-value) 을 통계검정 결과에 같이 제시해야 하고 독자들에게 해석의 여지를 남겨 둬야 한다.
귀무가설 H0 가 ‘작은’ 값 α ( 혹은 작은 p-값 ) 에 의해 기각되었더라도, 이것이 귀무가설이 ‘많은 정도로 잘못’ 되었다는 것을 의미하는 것은 아니다. 이런 경우에는 귀무가설을 잘못 기각할 (귀무가설 H0 가 참일 때) 확률이 작다 (type Ⅰ error 의 확률이 작다) 는 것을 의미한다. 그리고 반드시 혼동하지 말아야 하는 부분은 통계적 유의 (statistical significance) 와 실제 유의 (practical significance) 를 동일시 해서는 안 된다 는 것이다. 앞 포스트의 예제2. 에서 풀이한 것과 같이, p-값 0.0124 는 작은 값이고, 결과는 α ≥ 0.0124 인 모든 α 값에 대해 통계적으로 유의하다고 할 수 있다. 그러나, 남·여 표본의 반응 시간의 평균의 차이는 0.2 초에 불과하다. 결과가 실제적으로 유의할 수도 있고 그렇지 않을 수도 있다. 실제적인 유의를 판별하기 위해서는 \mu_1 - \mu_2 의 신뢰구간으로 표현해 봐야 한다.
마지막으로 단측 검정 (one-sided tests) 의 귀무가설을 선택하는데 있어서 우리가 사용한 방식에 대한 코멘트이다. 앞 포스트의 예제1. 에서 우리는 대립가설 Ha : p < 0.5 의 적합한 귀무가설로 H0 : p = 0.5 를 사용했다. 검정 통계량 Y 는 John 을 지지하는 유권자의 수였고, 표본의 수 n = 15 였다. 하나의 기각역은 { y ≤ 2 } 였다. 아마도 왜 귀무가설로서 H0* : p ≥ 0.5 를 사용하지 않았는지에 대해 궁금할 것이다. 왜냐하면 H0* : p ≥ 0.5 또는 Ha : p < 0.5 가 모든 p 의 범위를 나타내기 때문이다. 그렇다면 왜 우리가 H0 : p = 0.5 로 사용했는가? 결론부터 이야기하자면, 우리가 진짜로 관심 있는 것은 대립가설 Ha : p < 0.5 이기 때문이다. : 귀무가설은 우리의 주된 관심사가 아니다. 앞서 살펴 보았지만, 우리는 대개 귀무가설을 채택하지 않는 편이다. 덧붙이자면, H0 : p = 0.5 가 더 복잡한 형태의 H0* : p ≥ 0.5 를 다루기 위한 추가적인 방법을 도입하지 않더라도 동일한 α 값을 갖는 정확히 일치하는 결론에 다다를 수 있는 방법이기 때문이다. H0 : p = 0.5 를 귀무가설로 사용할 때, α 검정 수준을 계산하는 것은 상대적으로 간단하다. : 단지 P(Y ≤ 2 when p = 0.5) 를 찾으면 된다. 하지만 귀무가설로 H0* : p ≥ 0.5 를 사용하면, P(Y ≤ 2) 가 p (p ≥ 0.5) 의 함수가 되기 때문에 앞선 α의 정의는 불충분하다. 이런 경우에는 α 가 P(Y ≤ 2) 값의 최대 값 (p ≥ 0.5 를 만족하는 모든 p 에 대해서) 이 된다. 비록 그 결과를 여기서 유도하지는 않겠지만, max_{p \geq 0.5} P(Y \leq 2) 는 p = 0.5 , 즉 H0* : p ≥ 0.5 인 p 의 경계 값 (boundary value) 인 경우, 일 때가 된다. 따라서 단순히 H0 : p = 0.5 를 사용하더라도 올바른 α 값을 얻을 수 있는 것이다. 지금까지 살펴본 모든 검정 결과와 앞으로 살펴볼 내용에 마찬가지로 적용되는 부분이다. 즉, Ha : θ > θ0 를 적당한 연구 가설로 설정하면, \alpha = max_{\theta \leq \theta_0} P(test statistic in RR) 은 θ = θ0 일 때 발생하고, 이것은 θ 의 경계 값이 된다. 마찬가지로 Ha : θ < θ0 의 경우, \alpha = max_{\theta \geq \theta_0} P(test statistic in RR) 은 θ = θ0 일 때 발생한다. 따라서 추가적인 고려사항 없이도 H0*: θ ≥ θ0 대신 H0 : θ = θ0 를 사용한다면 올바른 검정 절차에 의해 올바른 α 를 계산하는데 문제가 없다고 할 수 있다.
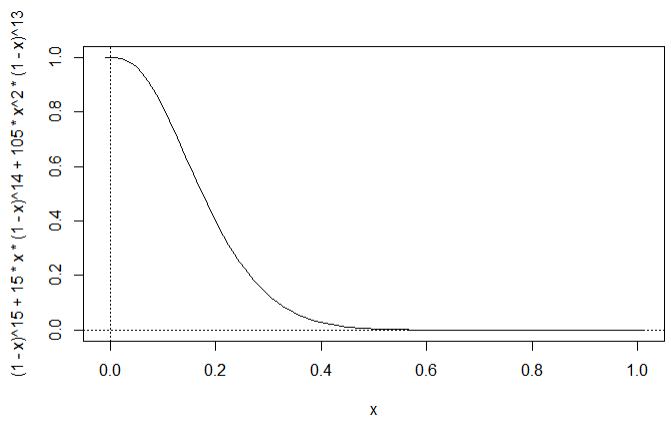
아래 그림은 P(Y ≤ 2) 를 이항분포를 사용하여 계산한 후 (0~1) 사이의 p 값에 대해 그래프를 그려본 것이다. 그림에서 확인 할 수 있겠지만 max_{p \geq 0.5} P(Y \leq 2) 는 p = 0.5 , 즉 H0* : p ≥ 0.5 인 p 의 경계 값 (boundary value) 인 경우임을 그래프를 통해서도 확인 가능하다.
P(Y \leq 2)=\binom{15}{0} p^0 (1-p)^{15} +\binom{15}{1} p^1 (1-p)^{14} +\binom{15}{2} p^2 (1-p)^{13}= (1-p)^{15}+ 15p(1-p)^{14}+ 105p^2(1-p)^{13}