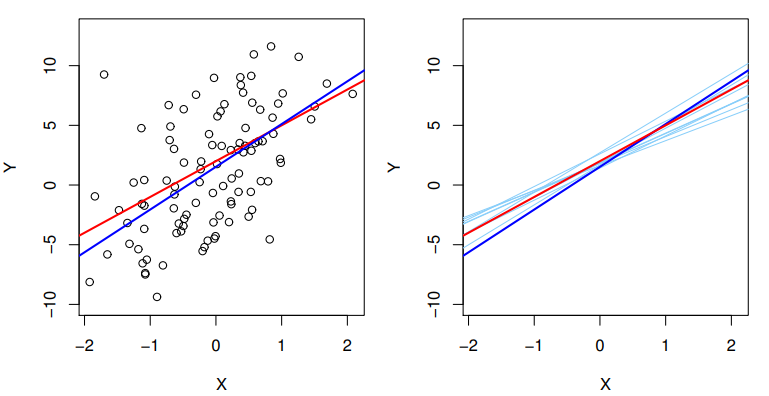
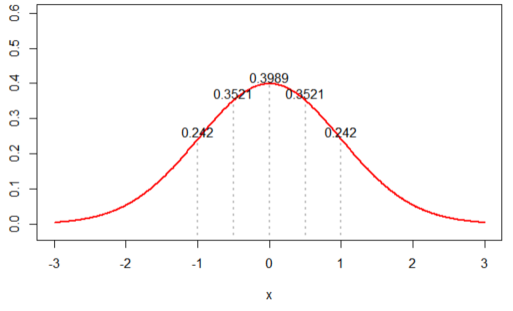
Note1. Convex Optimization Problem 01.
Note1. [PDF Link] Below notes were taken by my iPad Pro 3.0 and exported to PDF files. All contents were based on “Optimization for AI (AI505)” lecture notes at KAIST. For the supplements, lecture notes from Martin Jaggi [link] and “Convex Optimization” book of Sebastien Bubeck [link] were used. If you will have found any license issue, …